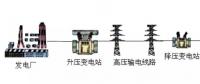
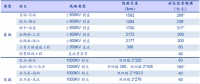
用電行為模式識別的理論和方法
1.數據預處理方法
通過對屬性進行規范化將屬性值按比例縮放,對于涉及神經網絡的分類算法將有助于加快學習階段的速度。對于基于距離的方法,規范化可以幫助防止具有較大初始值域的屬性與具有較小初始值域的屬性(如二元屬性)相比權重過大。目前常用的規范化方法有最大最小值規范化、平均數方差法、總和規范化、極大值規范化等。當使用同一聚類算法并以不同的規范化方式處理時,聚類結果往往不同,規范化方式的選擇對聚類效果影響很大,必須在負荷模式提取中加以考慮。這就要求在負荷模式提取時首先了解每種聚類方法在采用不同規范化方法時的性能好壞,以便得到準確可靠的聚類結果。
2.負荷模式識別的聚類方法
負荷模式提取通常用聚類技術實現,主要方法可分為如下幾類
(1)基于劃分的方法。基于劃分的聚類算法的基本思想為:給定一個含有m個對象的數據集,劃分方法將構建k個分組,每個分組就代表一個聚類簇。而且每個簇至少包括1個對象,每個對象必須且僅屬于1個簇。對于給定的數據集,算法首先根據給定的要構建劃分的數目創建個初始的分組,然后采用一種迭代重定位的方法改變初始分組,使得每一次改進以后的分組方案都較前一個好。
(2)層次聚類方法。層次方法根據層次的分解方式不同可以分為凝聚的或分裂的。凝聚的方法為自底向上分解,首先將每個對象作為單獨的一個組,然后合并相似的組,直到所有的組合并成一個(或滿足某個終止條件)。分裂的方法為自頂向下分解,首先將所有的對象置于一個組中,在迭代的每一步中,一個組被分裂為更小的組,直到最終每個對象在單獨的一個組中(或滿足某個終止條件)
(3)基于密度的方法。基于密度的方法與大部分劃分方法不同,它不是基于各種各樣的距離,而是基于密度:其主要思想是:只要臨近區域的密度(對象或數據點的數目)超過某個閾值,就繼續聚類。該方法既可以過濾噪聲數據,也可以發現任意形狀的簇。
(4)基于模型的方法。基于模型的方法通過優化給定的數據和某些數學模型之間的擬合。主要包括統計學方法和神經網絡方法
(5)模糊聚類。傳統聚類算法是一種硬劃分,把每個待識別對象嚴格劃分到每個類中,劃分界限是分明的。然而大多數對象實際上并沒有嚴格的屬性劃分,其在形態和類屬方面存在著中間性。利用模糊理論來處理聚類問題的方法稱為模糊聚類分析。模糊聚類分析是對傳統硬劃分方法的一種改進,樣本屬于各個類別的隸屬度表達了樣本屬性的中間性。

責任編輯:售電小陳
-

權威發布 | 新能源汽車產業頂層設計落地:鼓勵“光儲充放”,有序推進氫燃料供給體系建設
2020-11-03新能源,汽車,產業,設計 -

中國自主研制的“人造太陽”重力支撐設備正式啟運
2020-09-14核聚變,ITER,核電 -

探索 | 既耗能又可供能的數據中心 打造融合型綜合能源系統
2020-06-16綜合能源服務,新能源消納,能源互聯網
-
新基建助推 數據中心建設將迎爆發期
2020-06-16數據中心,能源互聯網,電力新基建 -

泛在電力物聯網建設下看電網企業數據變現之路
2019-11-12泛在電力物聯網 -

泛在電力物聯網建設典型實踐案例
2019-10-15泛在電力物聯網案例



-
權威發布 | 新能源汽車產業頂層設計落地:鼓勵“光儲充放”,有序推進氫燃料供給體系建設
2020-11-03新能源,汽車,產業,設計 -
中國自主研制的“人造太陽”重力支撐設備正式啟運
2020-09-14核聚變,ITER,核電 -

能源革命和電改政策紅利將長期助力儲能行業發展
-
探索 | 既耗能又可供能的數據中心 打造融合型綜合能源系統
2020-06-16綜合能源服務,新能源消納,能源互聯網 -

5G新基建助力智能電網發展
2020-06-125G,智能電網,配電網 -

從智能電網到智能城市