電力消費大數據智能分析技術——用電大數據分析平臺
5.2.3 用電大數據分析平臺
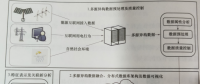
參照云計算技術體系結構與處理工具,并結合電力用戶側大數據分析的實際需要,搭建以分析計算為主的電力用戶側大數據管理平臺,其基本架構如圖5-24所示,分為應用層、私有云計算層、數據管理層。
此框架主要是結合云計算技術,利用 Hadoop搭建電力用戶側大數據管理平臺,在平臺上采用HDFS( Hadoop分布式文件系統)、HBase ( hadoop數據庫)與Hive( Hadoop數據倉庫工具)建立大數據存儲系統,在平臺上搭建 MapReduce并行化計算框架和 Spark內存并行化計算框架作為大數據計算分析系統,對電力用戶側的大數據進行分析。
數據管理層主要是對數據進行采集和集成整合。數據采集主要包括從智能電表、 SCADA系統和各種傳感器中采集的數據,這些數據不僅包括電網內部的數據,還包括大量相關的數據,這些數據由不同產商的設備產生,模態千差萬別,各單位數據口徑不一,形成了海量異構數據流,加工整合困難。這些數據的集成整合主要是指將傳統系統產生的數據遷移至私有云平臺,進行高效的管理。
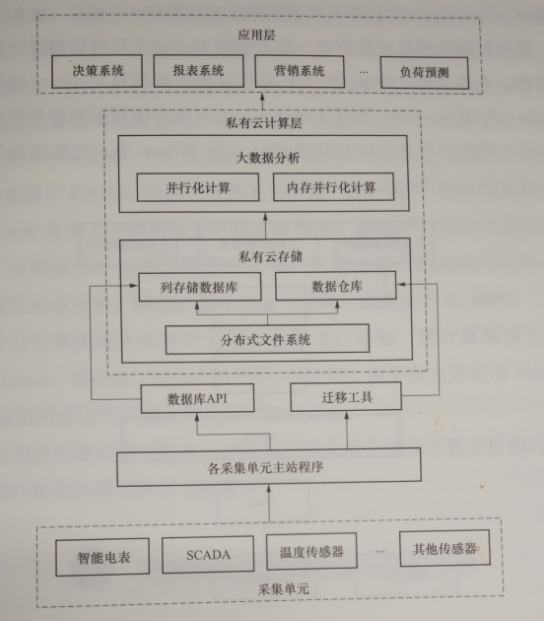
圖5-24用電大數據分析架構
雖然各廠商都提供了相應的應用程序編程接口(application pro-gramming interface,API),但其自動化程度并不高。簡單地使用API對大數據進行操作效率不高,需要使用第三方工具進行操作,如Sqoop和Datanucleus等。Sqoop是一款在Hadoop和關系數據庫之間進行相互轉移數據的工具,利用Sqoop可以使各個子系統的數據在大數據平臺上進行整合。 Datanucleus是一款開源的java持久化工具,可以對HBase、 Cassandra多種非關系型數據庫進行操作。
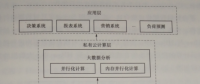
平臺針對數據集成整合這一難點采用Sqoop工具對數據進行抽取整合工作,將各個獨立的系統產生的數據及歷史數據利用Sqoop抽取整合到Hive與HBase中。使用Datanucleus對列存儲數據庫進行操作,將基于云計算的應用產生的在線數據寫入到HBase中。大數據的抽取整合流程如圖5-25所示。
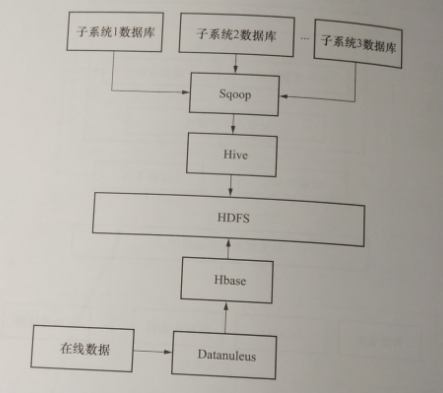
圖5-25用電大數據整合抽取流程
云計算層利用Hadoop搭建而成,大數據存儲在分布式文件系統HDFS中,利用Hive、Pig和HBase對數據進行管理,電力大數據在存儲方面已進行了一些研究,例如有文獻提出利用云計算存儲、運算技術進行電力數據中心的搭建;有文獻在云計算平臺上將數據映射成數據空間的點集,充分利用計算存儲資源,實現數據集到數據中心的布局方案;有文獻在對數據進行存儲時考慮到數據的安全性,利用HBase高性能優勢和現代密碼技術,將密鑰與密文的管理分離,開發了基于Ha-doop的智能電網數據安全存儲原型系統。該平臺利用HBase存儲電力負荷數據和相關數據, HBase數據庫是列為存儲單元的,方便對整列數據進行查詢,而隨后使用的隨機森林算法在學習過程中需要多次對整列數據進行讀取計算,對數據的操作需求符合HBase數據存儲的特點。
利用并行化計算模型MapReduce對大數據進行并行化批量計算分析,而對數據密集型的迭代計算采用基于內存的并行化計算模型Spark。Spark是一個開源的分布式集群系統,用于大數據的快速處理分析。Spark克服了Hadoop在迭代計算上的不足,現已成為Apache的頂級項目。Spark提供了一種內存并行化計算框架,框架將作業所需數據讀入內存,所需數據時直接從內存中查詢,這樣比基于磁盤的MapReduce訪問數據的速度快,減少了作業的運行時間,也減少了IO操作。
并行計算模型主要是對大量的數據進行挖掘,其計算模型主要有MapReduce、Dremel、Dryad和Cascading等,該平臺主要利用Map Re-duce模型對電力用戶側大數據進行挖掘分析。
應用層主要是利用私有云計算集群強大的存儲和計算分析能力為企業各部門提供決策和指導功能接口。

責任編輯:電力交易小郭