《電力大數據》引發技術變革的電力大數據
3 引發技術變革的電力大數據
3.1 數據規模大,數據處理時效性要求高——傳統技術手段不能經濟地滿足業務性能需求
3.1.4實際案例:基于大數據的短期負荷預測
1、現狀和需求
電力系統短期負荷預測結果關系到電力系統調度運行和生產計劃的制定,準確的短期負荷預測結果有助于提高系統的安全性和穩定性,能夠減少發電成本。電網中短期負荷預測主要根據自然條件與人為影響等多個因素與負荷之間的非線性關系,在滿足一定準確度要求的條件下,確定未來幾天的負荷數據,其中負荷足指電力需求攝(功率)或用電量。負荷預測的建模與預測是根據歷史數據資料所包含的信息,建立理想的模型及處理隨機因素仍然是負荷預測的主要問題,影響負荷預測準確度的原因是多方面的,典體可分為以下三個方面:
1)影響因素的不確定性導致負荷規律難以把握。影響負荷走勢的因素包括溫度、降水等天氣因素,也包含重大設備檢修、重大文體活動等人為因素。這些因素呈現顯著的隨機性和不確定性,因此負荷時間序列的變化呈現非平穩的隨機過程:,
2)負荷預測模型的質量直接關乎預測準確度的高低,負荷預測模型的建模與預測是依據歷史數據資料所包含的信息,因此預測模型反映歷史數據所包含信息的有效性和程度決定了預測水平的高低;
3)信息不完整由于大量用戶的用電行為與影響因素(如氣象因素)之間的關系在歷史數據中是沒有記載的,信息的缺失和不完整是無法避免的,這些因素是負荷預測誤差進一步減小的瓶頸。
2.應用場景
目前,電網公司根據其業務要求大踏步推進用電信息采集系統的建設。據國家電網公司相關報告指出,預計其用電信息采集系統智能電表數量到2015年將達到三億塊,用戶用電信息采集頻率更加頻繁:每15分鐘甚至每5分鐘就需要采集一次數據,且數據是雙向互動流轉,規模和頻率呈指數級增長。以河南省為例,河南全省實現全采集、全覆蓋后,用戶總量將達到4000萬,接入終端量接近300萬,采集數據總量接近60TB,年增量約為30TB。
實現對電網用戶的用電信息全采集,為準確把握用戶級負荷變化規律提供了數據基礎。目前調度部門短期負荷預測的對象主要針對總量負荷,或者再深一層次變電站的母線負荷,通過母線負荷累加獲得總量負荷。而電網負荷是由眾多用戶負荷構成,不同用戶的負荷受自身行業屬性和生產特點影響,負荷規律也是千差萬別,從電網負荷總量上分析負荷變化規律忽略了用戶的用電規律,因此分析結果必然存在一定的偏頗,更加無法精確定位負荷波動的源頭(即用戶)。而用電信息采集系統的海量用戶級負荷信息將使從用戶級負荷入手的短期負荷預測成為可能。
同時,隨著電網公司GIS數據平臺等業務輔助平臺的完善,以及多源數據平臺的融合,行業標準劃分數據、季節天氣等與短期負荷密切耦合的相關因素數據也將會納入到短期負荷預測的基礎數據庫中。眾所周知,負荷的影響因素眾多、非線性極強。結合負荷數據與影響因素數據,研究負荷隨多種因素的變化規律。進而總結用戶的用電規律,將是提高短期負荷預測準確度的一種有效手段。
3.大數據解決方案
電網公司現有數據源頭已經可以定位至用戶級負荷層面,結合其完備的業務輔助平臺數據庫,在這里,我們提出一個基于大數據技術的短期負荷預測解決方案。
該方案的主體思路是采用對每個用戶的負荷進行獨立預測,最后累加的方法。數據源為電網用電信息采集系統數據庫及相關影響因素數據庫,軟件采用大數據技術(如聚類分析、灰色關聯分析、決策樹等)對負荷數據進行預處理,把握每個用戶負荷與天氣、日類型等影響因素的密切關系,并根據不同用戶特性構建預測模型,最后累加所有用戶的預測結果得到系統預測負荷,原理框架如下圖所示。
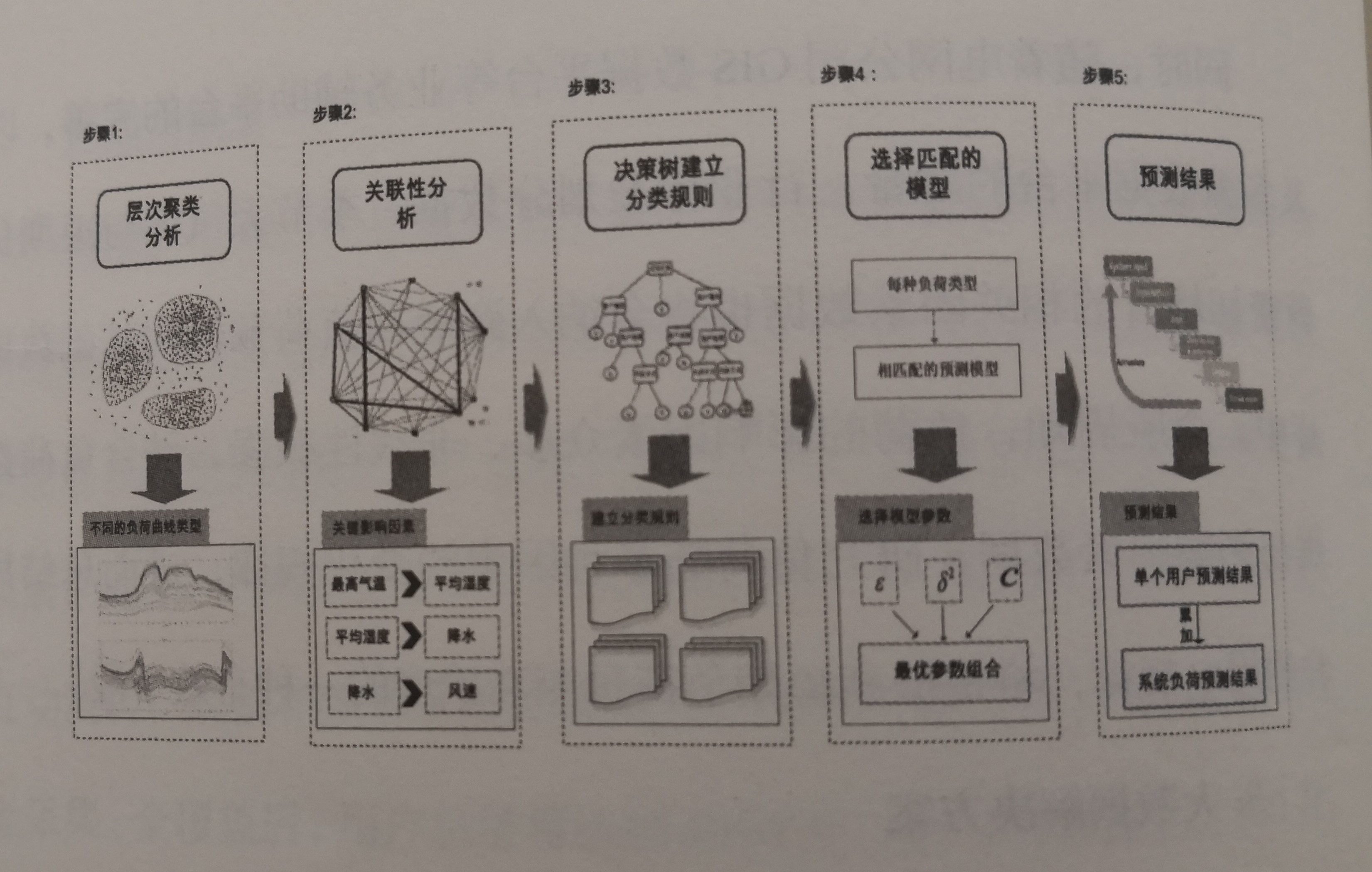
下面,將詳細介紹組成該方案的五個步驟。
步驟1:負荷曲線聚類分析
甶于負荷曲線的走勢與日類型、天氣因素等密切相關,對歷史負荷曲線的聚類分析是負荷預測的基礎步驟。針對海量的用戶負荷,若無針對性地研究每個用戶的用電規律將會造成巨大的資源浪費。因此,合理的數據挖掘技術(即聚類分析)能夠將用電規律相近的負荷日期歸為一類。聚類分析技術通過計算各個向量之間的空間距離,將其由零散分布的獨立樣本逐漸歸為趨勢相近的若干類。
步驟2:確立關鍵影響因素
對影響負荷的因素進行關聯度排序,剔除一些對負荷影響小的因素,從而達到約簡分類規則,簡化預測模型的目的。
在關聯分析方法中,灰色關聯分析法是一種應用較多,效果得到普遍公認的關聯度量化方法。采用該算法計算每個因素[如日最高氣溫,日平均氣溫、平均濕度、日類型(星期幾)等]與負荷曲線之間的灰色關聯度、將預測日前一年的歷史負荷數據、氣象數據以及日類型數據集作為分析樣本,設定母序列為負荷值,天氣因素、日類型為若干子序列。采用灰色關聯分析算法分析各個子序列與母序列的相關性,最后將一年每天的灰色關聯度求均值即可得到各個影響因素的灰色關聯度。對灰色關聯度進行排序,選定值較大的前四個作為影響該用戶負荷的關鍵影響因素。
步驟3:建立分類規則
通過步驟1以及步驟2得到了待預測日過去一年的歷史負荷曲線的分類結果和影響負荷的關鍵因素。步驟3需要找到分類結果與關鍵影響因素間的耦合關系,即造成聚類結果的依據,并以分類規則的形式表現出來。該步驟的作用是當已知待預測日的關鍵影響因素值時,可以將預測口遵循分類規則分配到對應的聚類中去.從而該類的結果就可以作為預測日的相似日數據集來訓練模型。
CART決策樹算法是一種直觀的表征分類關系的規律表示方法,在每個節點(除葉節點外〉將選用Gini指數最小的關鍵影響因素.將當前節點的歷史負荷數據集分割為兩個子集,直到最后的分類結果與步驟1中的聚類結果吻合。該過程完成了對歷史負荷及關鍵影響因素數據與聚類結果間耦合關系的學習,能夠消楚完善地表征分類規則。
步驟4:將待測日分類
當得到預測日的關鍵因素日特征向量(即關鍵因素值組成的向量)后,將其輸入步驟3建立的決策樹模型中,即可輸出相應的分類結果。
步驟5:訓練預測模型并預測
針對步驟1的分類結果,將每類的負荷數據及相應的關鍵因素數據構建訓練樣本針對每類負荷數據的變化規律和特征,選取匹配的預測模型完成對該日負荷的預測。在這個過程中,我們選用支持向量機方法,該方法的核函數通常為RBF核函數,因為此核函數下需要確定的支持向量機參數有核參數,不敏感洗漱和懲罰參數。不同的參數組合,匹配不同類型的負荷,具有更強的建模針對性。根據步驟4中得出的待預測日的分類結果,選用對應的支持向量機模型完成預測。
步驟6: 計算系統負荷
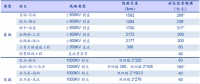
根據目標預測系統,針對系統中的每個用戶重復步驟1~5,該過程涉及的數據體量巨大,可以采用Hadoop大數據平臺進行計算,最后累加所有用戶負荷,并考慮網損即可得出最終的系統負荷。Hadoop大數據平臺的使用主要包括涉及HDFS和HBase的數據存儲和管理系統,下表為該預測方案針對該地區120萬負荷的預測在Hadoop大數據平臺上實現的效果,預測結果滿足短期負荷預測時間要求。
表3-1Hadoop大數據平臺的預測效果

書名:電力大數據:能源互聯網時代的電力企業轉型與價值創造
ISBN:978-7-111-51693-4
作者:賴征田
出版日期:2016-01
出版社:機械工業出版社

責任編輯:繼電保護
-

權威發布 | 新能源汽車產業頂層設計落地:鼓勵“光儲充放”,有序推進氫燃料供給體系建設
2020-11-03新能源,汽車,產業,設計 -

中國自主研制的“人造太陽”重力支撐設備正式啟運
2020-09-14核聚變,ITER,核電 -

探索 | 既耗能又可供能的數據中心 打造融合型綜合能源系統
2020-06-16綜合能源服務,新能源消納,能源互聯網
-
新基建助推 數據中心建設將迎爆發期
2020-06-16數據中心,能源互聯網,電力新基建 -

泛在電力物聯網建設下看電網企業數據變現之路
2019-11-12泛在電力物聯網 -

泛在電力物聯網建設典型實踐案例
2019-10-15泛在電力物聯網案例



-
權威發布 | 新能源汽車產業頂層設計落地:鼓勵“光儲充放”,有序推進氫燃料供給體系建設
2020-11-03新能源,汽車,產業,設計 -
中國自主研制的“人造太陽”重力支撐設備正式啟運
2020-09-14核聚變,ITER,核電 -

能源革命和電改政策紅利將長期助力儲能行業發展
-
探索 | 既耗能又可供能的數據中心 打造融合型綜合能源系統
2020-06-16綜合能源服務,新能源消納,能源互聯網 -

5G新基建助力智能電網發展
2020-06-125G,智能電網,配電網 -

從智能電網到智能城市