【知識】正則化與過擬合
- 過擬合怎么理解?如何解決?
- 正則化怎么理解?如何使用?
在機器學習中有時候會出現(xiàn)過擬合,為了解決過擬合問題,通常有兩種辦法,第一是減少樣本的特征(即維度),第二就是我們這里要說的“正則化”(又稱為“懲罰”,penalty)。
從多項式變換和線性回歸說起
在非線性變換小節(jié)中,我們有討論Q次多項式變換的定義和其包含關(guān)系,這里如果是10次多項式變換,那么系數(shù)的個數(shù)是11個,而2次多項式的系數(shù)個數(shù)是3。從中我們可以看出,所有的2次多項式其實是10次多項式加上一些限制,即w3=w4=...=w10=0。

基于上面的討論,我們希望能將二次多項式表示成十次多項式再加上一些約束條件,這一步的目的是希望能拓寬一下視野,在推導后面的問題的時候能容易一些。
這個過程,我們首先要將二次多項式的系數(shù)w拓展到11維空間,加上w3=w4=...=w10=0這個條件得到假設(shè)集合H2;然后為了進一步化簡,我們可以將這個條件設(shè)置的寬松一點,即任意的8個wi為0,只要其中有三個系數(shù)不為0就行,得到一組新的假設(shè)空間H2',但這個問題的求解是一個NP-hard的問題,還需要我們修正一下;最后,我們還需要將這個約束條件進一步修正一下得到假設(shè)集合H(C),給系數(shù)的平方的加和指定一個上限,這個假設(shè)集合H(C)和H2'是有重合部分的,但不相等。
最后,我們把H(C)所代表的假設(shè)集合稱為正則化的假設(shè)集合。
下圖表示了這個約束條件的變化:

正則化的回歸問題的矩陣形式
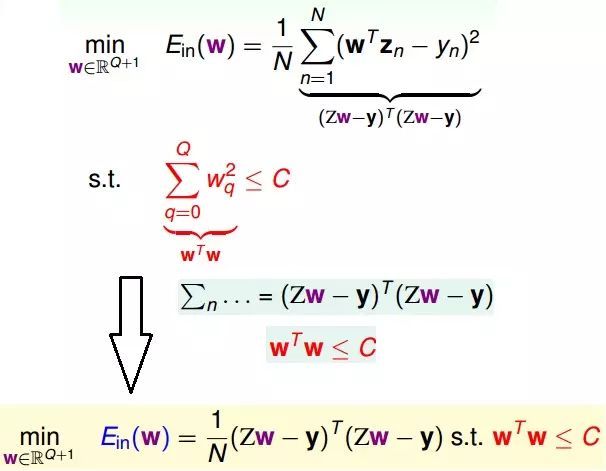
由上圖所示,我們現(xiàn)在要求解的是在一定約束條件下求解最佳化問題,求解這個問題可以用下面的圖形來描述。
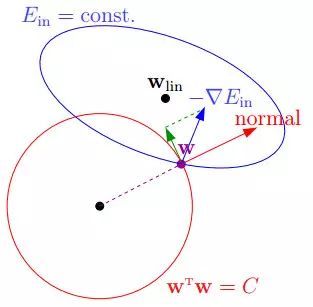
本來要求解Ein的梯度,相當于在一個橢圓藍色圈中求解梯度為零的點,而下面這個圖表示,系數(shù)w在半徑是根號C的紅色球里面(w需要滿足的約束條件),求解藍色區(qū)域使得梯度最小的點。
那么,最優(yōu)解發(fā)生在梯度的反方向和w的法向量是平行的,即梯度在限制條件下不能再減小。我們可以用拉格朗日乘數(shù)的方法來求解這個w。


Ridge Regression
Ridge Regression是利用線性回歸的矩陣形式來求解方程,得到最佳解。

Augmented Error
我們要求解這個梯度加上w等于0的問題,等同于求解最小的Augmented Error,其中wTw這項被稱為regularizer(正則項)。我們通過求解Augmented Error,Eaug(w)來得到回歸的系數(shù)Wreg。這其實就是說,如果沒有正則項的時候(λ=0),我們是求解最小的Ein問題,而現(xiàn)在有了一個正則項(λ>0),那么就是求解最小的Eaug的問題了。

不同的λ造成的結(jié)果
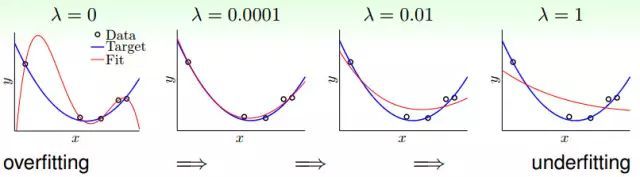
從上圖可以看出,當λ=0的時候就會發(fā)生過擬合的問題,當λ很小時(λ=0.0001),結(jié)果很接近理想的情況,如果λ很大(λ=1),會發(fā)生欠擬合的現(xiàn)象。所以加一點正則化(λ很小)就可以做到效果很好。
正則化和VC理論
我們要解一個受限的訓練誤差Ein的問題,我們將這個問題簡化成Augmented Error的問題來求解最小的Eaug。
原始的問題對應(yīng)的是VC的保證是Eout要比Ein加上復(fù)雜度的懲罰項(penalty of complexity)要小。而求解Eaug是間接地做到VC Bound,并沒有真正的限制在H(C)中。
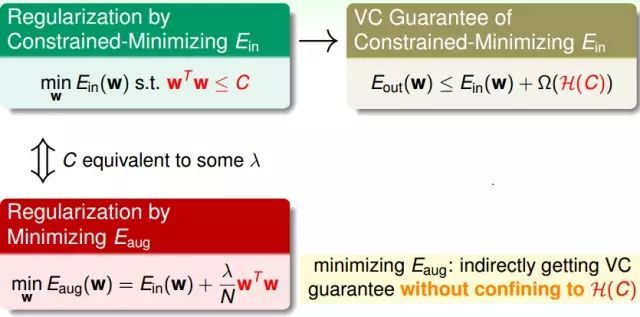
wTw可以看成是一個假設(shè)的復(fù)雜度,而VC Bound的Ω(H)代表的是整個假設(shè)集合有多么的復(fù)雜(或者說有多少種選擇)。
這兩個問題都好像是計算一個問題的復(fù)雜度,我們該怎么聯(lián)系著兩種復(fù)雜度的表示方式呢?其理解是,一個單獨的很復(fù)雜的多項式可以看做在一類很復(fù)雜的假設(shè)集合中,所以Eaug可以看做是Eout的一個代理人(proxy),這其實是我們運用一個比原來的Ein更好一點點代理人Eaug來貼近好的Eout。

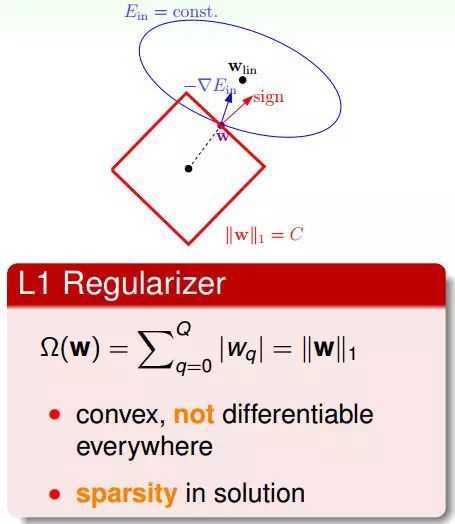
一般性的正則項 L1 Regularizer
L1 Regularizer是用w的一范數(shù)來算,該形式是凸函數(shù),但不是處處可微分的,所以它的最佳化問題會相對難解一些。
L1 Regularizer的最佳解常常出現(xiàn)在頂點上(頂點上的w只有很少的元素是非零的,所以也被稱為稀疏解sparse solution),這樣在計算過程中會比較快。
L2 Regularizer
L2 Regularizer是凸函數(shù),平滑可微分,所以其最佳化問題是好求解的。

最優(yōu)的λ
噪聲越多,λ應(yīng)該越大。由于噪聲是未知的,所以做選擇很重要,我將在下一小節(jié)中繼續(xù)接受有關(guān)參數(shù)λ選擇的問題。
總結(jié)
過擬合表現(xiàn)在訓練數(shù)據(jù)上的誤差非常小,而在測試數(shù)據(jù)上誤差反而增大。其原因一般是模型過于復(fù)雜,過分得去擬合數(shù)據(jù)的噪聲和異常點。正則化則是對模型參數(shù)添加先驗,使得模型復(fù)雜度較小,對于噪聲以及outliers的輸入擾動相對較小。
正則化符合奧卡姆剃刀原理,在所有可能選擇的模型,能夠很好的解釋已知數(shù)據(jù)并且十分簡單才是最好的模型,也就是應(yīng)該選擇的模型。從貝葉斯估計的角度看,正則化項對應(yīng)于模型的先驗概率,可以假設(shè)復(fù)雜的模型有較小的先驗概率,簡單的模型有較大的先驗概率。
參考資料
機器學習中的范數(shù)規(guī)則化之(一)L0、L1與L2范數(shù)
http://blog.csdn.net/zouxy09/article/details/24971995
機器學習中的范數(shù)規(guī)則化之(二)核范數(shù)與規(guī)則項參數(shù)選擇
http://blog.csdn.net/zouxy09/article/details/24972869
作者Jason Ding
http://blog.csdn.net/jasonding1354/article/details/44006935#comments
官方微信售電那點事兒")
責任編輯:售電衡衡
- 相關(guān)閱讀
- 泛在電力物聯(lián)網(wǎng)
- 電動汽車
- 儲能技術(shù)
- 智能電網(wǎng)
- 電力通信
- 電力軟件
- 高壓技術(shù)
-

權(quán)威發(fā)布 | 新能源汽車產(chǎn)業(yè)頂層設(shè)計落地:鼓勵“光儲充放”,有序推進氫燃料供給體系建設(shè)
2020-11-03新能源,汽車,產(chǎn)業(yè),設(shè)計 -

中國自主研制的“人造太陽”重力支撐設(shè)備正式啟運
2020-09-14核聚變,ITER,核電 -

探索 | 既耗能又可供能的數(shù)據(jù)中心 打造融合型綜合能源系統(tǒng)
2020-06-16綜合能源服務(wù),新能源消納,能源互聯(lián)網(wǎng)
-
新基建助推 數(shù)據(jù)中心建設(shè)將迎爆發(fā)期
2020-06-16數(shù)據(jù)中心,能源互聯(lián)網(wǎng),電力新基建 -

泛在電力物聯(lián)網(wǎng)建設(shè)下看電網(wǎng)企業(yè)數(shù)據(jù)變現(xiàn)之路
2019-11-12泛在電力物聯(lián)網(wǎng) -

泛在電力物聯(lián)網(wǎng)建設(shè)典型實踐案例
2019-10-15泛在電力物聯(lián)網(wǎng)案例
-

新基建之充電樁“火”了 想進這個行業(yè)要“心里有底”
2020-06-16充電樁,充電基礎(chǔ)設(shè)施,電力新基建 -

燃料電池汽車駛?cè)雽こ0傩占疫€要多久?
-

備戰(zhàn)全面電動化 多部委及央企“定調(diào)”充電樁配套節(jié)奏
-
權(quán)威發(fā)布 | 新能源汽車產(chǎn)業(yè)頂層設(shè)計落地:鼓勵“光儲充放”,有序推進氫燃料供給體系建設(shè)
2020-11-03新能源,汽車,產(chǎn)業(yè),設(shè)計 -
中國自主研制的“人造太陽”重力支撐設(shè)備正式啟運
2020-09-14核聚變,ITER,核電 -

能源革命和電改政策紅利將長期助力儲能行業(yè)發(fā)展
-
探索 | 既耗能又可供能的數(shù)據(jù)中心 打造融合型綜合能源系統(tǒng)
2020-06-16綜合能源服務(wù),新能源消納,能源互聯(lián)網(wǎng) -

5G新基建助力智能電網(wǎng)發(fā)展
2020-06-125G,智能電網(wǎng),配電網(wǎng) -

從智能電網(wǎng)到智能城市