數據熱圖與內存計算自動化協同優化
0 引言
在大數據和云計算熱潮中,內存數據庫市場的復合年增長率為43%(全球研究公司Markets&Markets預測),從2013年的22.1億美元躍升至2018年的132.3億美元。內存計算最重要的驅動力來自內存數據庫允許對“實時”事務數據的實時分析和實時的情境意識,而不是對“過時數據”進行事后分析。
更多公司正在采用或者計劃采用實時分析,這樣做的驅動是來自增加業務流程的速度和準確性的壓力,特別在數字業務和物聯網方面。隨著數據規模越來越大,從萬億字節(TB)到千萬億字節(PB)級;一部智能手機每日可產生30 MB左右的數據量,而一座高自動化的工業4.0的工廠,一天產生的數據可以超過一個PB。大數據所帶來的大規模及需要實時處理等特點與傳統的以計算為中心的模式產生巨大矛盾,使得傳統計算模型難以適應當今大數據環境下的數據處理。數據處理從以計算為中心轉變成以數據為中心,通過使用傳統的內存—磁盤訪問模式處理大數據存在I/O瓶頸,處理的速度問題愈發突出,且時效性難以保證,現有的方案都只能一定程度上緩解這個瓶頸。每家大型公司每分鐘都會做出數千次實時決策,企業的需求使得內存計算技術成為目前廣受關注的技術。本文研究了從海量數據中識別出哪些數據是真正的熱點數據,然后根據數據的熱度,分別將數據放入列式內存、行式內存、閃存和硬盤,進行存儲的智能分級管理,進而通過內存計算技術支持企業級實時計算需求[1]。
1 數據庫內存計算
內存計算的概念最早被提出是在20世紀90年代,當時硬件發展有限,沒有得到進一步深入研究。直至2010年以后,隨著內存價格大幅下降,內存容量增長,將大量數據存入專用服務器內存得以實
現[2]。而真正在企業級核心系統中運用最成功的方式是Database In-Memory,即內存數據庫。關系型數據庫管理系統(Relational Database Management System,RDBMS)作為企業核心數據的管理系統,如果具備內存計算能力,可以直接使企業的業務系統獲得實時計算的能力。這個領域也涌現出眾多的技術方案,其中Oracle的Oracle Database In-Memory選件是應用較為成功的技術,可以支持用戶在不修改原有程序的情況下,快速實現內存計算,透明地加速分析查詢[3],從而大幅度提升計算性能,實現實時業務決策。
Oracle Database In-Memory技術要點是同時以行、列2種形式緩存數據[4]。Oracle數據庫傳統上以行格式存儲數據。在一個行格式數據庫中,數據在數據庫中以行式存儲,每行數據包含多列,每列代表關于該記錄的不同屬性。行格式是聯機事物處理系統(Online Transaction Processing,OLTP)的理想選擇,給定記錄的所有屬性順序保存在一起,可以快速訪問記錄中的所有列。列格式數據庫將記錄的每個屬性以列的形式存儲,列格式是聯機分析系統(On-Line AnalysisProcessing,OLAP)的理想選擇,因為它只允許更快的數據檢索[5]。
Oracle Database In-Memory支持在內存中同時緩存行、列2種格式,這種雙格式的內存計算架構不會增加太多的內存開銷,通過數據壓縮和內存存儲優化,增加列式緩存后內存開銷只增大約20%[6]。相對于性能方面的提升,內存方面為了獲得最佳性能而付出的代價是很小的。雙格式的內存計算架構如
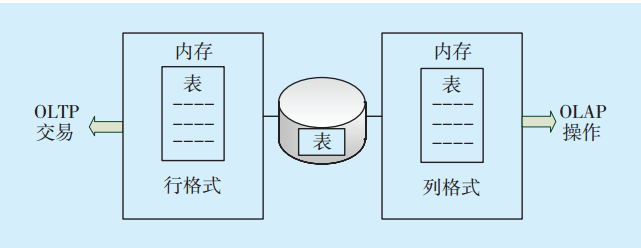 圖1 雙格式的內存計算架構Fig.1 Dual-format Database In-Memory architecture
圖1 雙格式的內存計算架構Fig.1 Dual-format Database In-Memory architecture
Database In-Memory做到了行列2種格式的共存,并且實現了2種格式數據的事物級一致性[7],使得OLAP業務通過內存計算提升性能,支持實時分析,同時還可以較少分析類索引數量,使得OLTP類業務性能也有提升,充分體現了內存計算的優勢。
2 數據熱圖
信息生命周期管理(Information Lifecycle Management,ILM)是根據企業當前的業務和性能需求將數據存儲在不同的存儲和壓縮層中,這種方法提供了優化存儲以節省成本和最大性能的可能性。
在Oracle Database 12c中包含2個ILM功能。一是數據熱圖(Heat Map),通過熱圖可以聚合大量數據,使用直觀的方式表現數據的溫度,自動跟蹤在行和段級別的修改和查詢時間戳,提供有關如何訪問數據的詳細信息[8-9]。二是自動數據優化(Automatic Data Optimization,ADO),根據熱圖收集的信息,利用用戶定義的策略自動移動和壓縮數據。Heat Map和ADO可以利用Oracle數據庫壓縮和分區技術降低管理大量數據的成本,同時還能提高應用程序和數據庫性能。
數據熱圖可以細粒度地跟蹤數據使用情況,跟蹤行和段級別的表/分區使用信息,以及在行級別跟蹤數據修改時間、全表掃描時間,聚合到塊級別,并在段級跟蹤索引查找時間。熱圖提供了數據使用情況的詳細視圖,以及訪問模式如何隨時間變化的信息。數據熱圖示例如
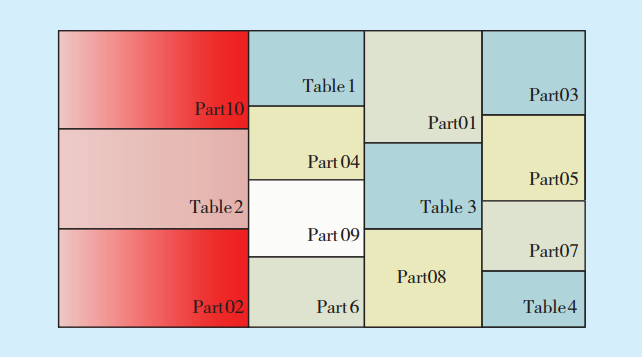 圖2 數據熱圖示例Fig.2 Heat map data example
圖2 數據熱圖示例Fig.2 Heat map data example
紅色說明數據最熱,黃色可以叫做溫數據。如果為藍色,則這類數據可以安全地移動到低級存儲設備(例如遷移到性能較低的廉價存儲),這種類型的數據也被稱為“過期數據”或“歸檔數據”。
企業級系統由于數據量龐大,如果簡單的將所有數據按照相同服務水平管理,如采用同一級別的存儲保存所有數據,則無法控制系統的成本或保證應用的性能。最關鍵或經常訪問的數據需要最佳的性能和可用性,但為所有數據提供這種最佳的訪問質量的存儲方案是昂貴的,低效的,并且在結構上通常是不可能做到的。因此需要實施數據存儲分層的分級管理。
通過存儲分層,可以將數據部署在不同的存儲層上,從而將較少訪問(較冷)的數據遷移出最昂貴、最快的存儲。較冷的數據仍然在線可用,但速度較慢,這是由于較冷數據的很少訪問對整體應用程序性能的影響最小。活躍程度更低的數據也可以在存儲中被壓縮到更高的水平。數據生命周期管理常用技術是存儲分層與數據壓縮。
數據存儲分級主要是內存、閃存、普通固態硬盤(Solid-State Disk,SSD)、機械磁盤與離線存儲的磁帶。SSD存儲設備與傳遞機械硬盤不同,SSD可以并行處理多個隨機存取請求,不會產生單個I/O請求降級導致的等待時間[10-11],組合多種介質和數據壓縮可以構造出更多的層次。
3 自動化協同架構
內存計算、數據熱圖和數據分級存儲3種技術各有側重。其中數據熱圖與數據分級存儲主要應用于數據生命周期管理,內存計算則用于實時分析。采用熱圖結合分級策略,將最需要的數據放入內存中,實現3種機制的自動化協同,達到在最低內存成本上的最大性能收益。內存計算、數據熱圖和數據分級存儲自動化調度模型如
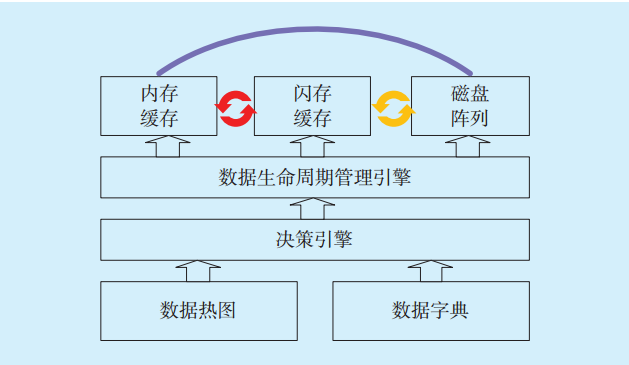 圖3 自動化調度模型Fig.3 Automated scheduling model
圖3 自動化調度模型Fig.3 Automated scheduling model
3.1 決策引擎
決策引擎是系統的關鍵部分,旨在優化數據庫中的數據分析類操作,基于知識庫分析數據庫中存在的分析處理工作負載,推薦需要加載或卸載出內存的數據,并提供決策實施后估計收益。
決策引擎主要有3部分組成:策略庫、熱圖、模式匹配模塊。決策引擎工作模式如
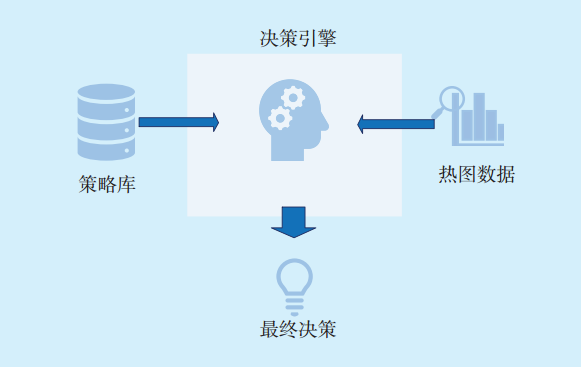 圖4 決策引擎工作模式Fig.4 Decision engine working mode
圖4 決策引擎工作模式Fig.4 Decision engine working mode
決策引擎基于數據熱圖分析數據的溫度,根據對數據庫對象的SQL操作模式、活動會話歷史(Active Session History,ASH)的跟蹤數據,結合使用其他統計信息來分析數據的分區和分布情況。
預置的策略主要邏輯是消除用戶I / O等待、集群傳輸等待和緩沖區高速緩存鎖等待等數據庫等待事件,可以分析某些查詢處理的特點,推薦特定的壓縮類型。預置的策略是基于業務模式、數據庫建模和數據庫運維的經驗人工創建的。根據策略引擎的決策可以自動或人工確認后通過DBMS管理包進行對象加載/卸載操作。
策略庫中預定義了一些數據優化的規則。如:某表或分區累計30天沒有寫操作,沒有頻繁讀操作,則推薦進行列式壓縮;某表或分區累計30天有少量寫操作,多次全表掃描,則推薦加載到列式內存緩存區域;某表為時間分區表,按天分區。按業務規則,每天凌晨完成入庫,當日日間頻繁查詢,人工定義每日加入列式內存緩存區域,7天后卸載出內存。
策略庫隨著信息不斷收集入庫,逐漸豐富,決策越來越準確。策略庫結合數據熱圖中的熱點數據進行模式匹配,模式匹配將從熱圖中找到的熱點數據按照策略庫中提供的規則逐條過濾,發現符合條件的熱點數據,則按照策略向數據生命周期管理引擎發起操作請求。
決策引擎底層數據庫建模如
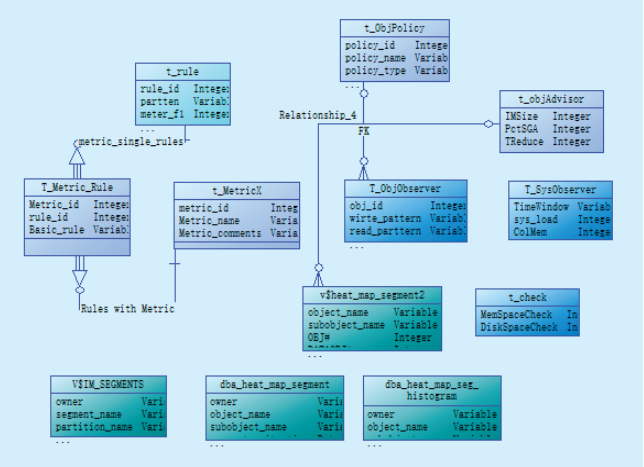 圖5 決策引擎數據庫建模Fig.5 Decision engine database modeling
圖5 決策引擎數據庫建模Fig.5 Decision engine database modeling
決策引擎的決策過程基于數據庫熱圖的幾個基礎視圖,如:v$heat_map_segment,以及本身策略庫的基礎表T_RULE和記錄決策引擎制定出的數據生命周期管理的方案T_OBJPOLICY,還有引擎運算使用的數據庫和操作系統各種狀態指標的采集表。
3.2 數據生命周期管理引擎
Oracle Database12cR1中推出了Automatic Data Op

責任編輯:售電衡衡
-

權威發布 | 新能源汽車產業頂層設計落地:鼓勵“光儲充放”,有序推進氫燃料供給體系建設
2020-11-03新能源,汽車,產業,設計 -

中國自主研制的“人造太陽”重力支撐設備正式啟運
2020-09-14核聚變,ITER,核電 -

探索 | 既耗能又可供能的數據中心 打造融合型綜合能源系統
2020-06-16綜合能源服務,新能源消納,能源互聯網
-
新基建助推 數據中心建設將迎爆發期
2020-06-16數據中心,能源互聯網,電力新基建 -

泛在電力物聯網建設下看電網企業數據變現之路
2019-11-12泛在電力物聯網 -

泛在電力物聯網建設典型實踐案例
2019-10-15泛在電力物聯網案例



-
權威發布 | 新能源汽車產業頂層設計落地:鼓勵“光儲充放”,有序推進氫燃料供給體系建設
2020-11-03新能源,汽車,產業,設計 -
中國自主研制的“人造太陽”重力支撐設備正式啟運
2020-09-14核聚變,ITER,核電 -

能源革命和電改政策紅利將長期助力儲能行業發展
-
探索 | 既耗能又可供能的數據中心 打造融合型綜合能源系統
2020-06-16綜合能源服務,新能源消納,能源互聯網 -

5G新基建助力智能電網發展
2020-06-125G,智能電網,配電網 -

從智能電網到智能城市