基于實時關聯分析算法及CEP的大數據安全分析模塊研究與實現
0 引言
在信息爆炸的互聯網社會,大數據滲透在生活的方方面面。大數據時代的企業網絡環境安全數據分析也呈現海量化、多樣化、異構化等特點。自“棱鏡門”事件的爆發[1],層出不窮的安全問題凸顯,從傳統病毒進化到蠕蟲、拒絕服務攻擊(Denial of Service,DoS)等惡意攻擊,乃至復雜程度更高的網絡攻擊手段——木馬、間諜軟件、僵尸網絡、網絡詐騙、網絡釣魚等,攻擊者已不僅僅滿足于使用單一的手段進行攻擊,而是使用關聯的、復雜的攻擊手段、模型及算法針對企業網絡環境中的薄弱部分進行攻擊[2]。面對企業內安全告警信息的特點及愈發復雜的攻擊手段,安全告警監控平臺的相關監控、分析及使用人員無所適從。因此,對企業網絡環境中接入的海量數據關聯分析生成告警的實時性、準確性及個性化等方面提出更嚴格的要求。
在傳統的大數據安全告警監控平臺中,安全告警是以數據為驅動[3-4],從經驗豐富的安全分析人員獲得。對海量安全數據的分析實際上是對安全事件的分析[5],但僅從數據入手,靠人工途徑獲得安全數據的關聯知識過程繁瑣[6-8],在不同的應用環境可能存在差異,更無法滿足實時性,從而無法滿足大數據安全分析告警監控的整體需要。因此,采用新技術相結合的自動化數據關聯分析生成告警顯得尤為
迫切。
在大數據環境下,本文基于上述海量安全事件分析的新要求,設計并實現了基于復雜事件處理(Complex Event Processing,CEP)的大數據安全關聯分析模型,使用Storm和Esper結合的事件處理框架,結合前置的數據采集模塊、后置的告警生成模塊,進行海量數據關聯分析與告警生成。此思路經過設計、研發并投入生產環境應用、驗證,自動化地進行海量數據分析,提取關鍵信息,生成告警,為安全分析相關人員提供了實時、準確、個性化的安全信息分析服務。
1 模型設計
大數據安全關聯分析及告警生成的實現通過完整平臺實現,設計重點是基于CEP的大數據安全關聯分析模型,故安全數據關聯分析的前置及后置模塊僅簡單介紹。復雜事件處理的數據關聯分析模型架構如
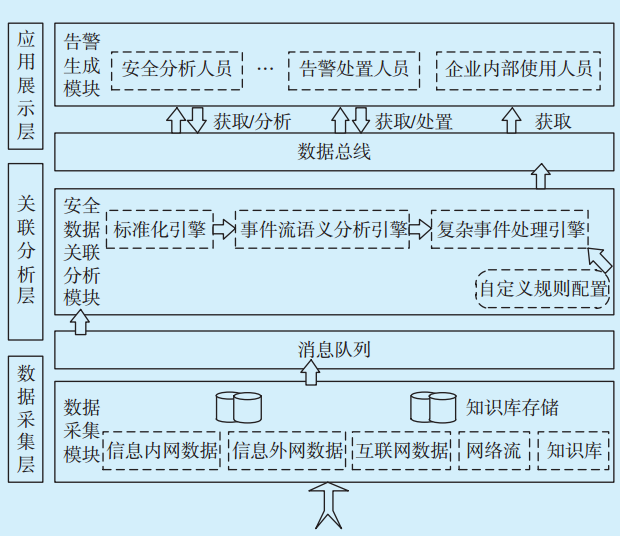 圖1 復雜事件處理的數據關聯分析模型架構Fig.1 Architecture of data association analysis module based on complex event processing
圖1 復雜事件處理的數據關聯分析模型架構Fig.1 Architecture of data association analysis module based on complex event processing
1.1 數據采集模塊
數據采集是海量數據關聯分析的前置,在實現安全關聯分析之前,需確保系統中有數據采集前置。數據采集模塊主要包括多源異構數據的采集、存儲及轉發。企業網絡環境中部署各類設備,數據采集模塊分布式統一采集從不同設備發送的日志數據,對數據進行初步抽取與處理,處理后的數據本地存儲一份,并推送至消息隊列中,推送的數據稱為安全事件流,是安全設備、網絡設備、應用服務器等采集到的一組數據、一個數據包、一類描述文件,這些事件按照設備報出來的形式,被視為一個安全原子事件[9],記為
其中:start_time和end_time分別表示事件的開始時間與結束時間,data表示日志其他的重要
屬性。
在企業網絡環境下,數據采集層隨時從不同設備、系統中接收并生成安全事件流,安全事件流可以看作是無間斷地主被動采集,類型相互關聯的數個原子事件
1.2 安全數據關聯分析模塊
數據采集完畢后,通過安全數據分析模塊對推送至消息隊列的安全復雜事件即安全數據進行數據關聯分析,安全數據關聯分析模塊按照安全數據處理事件選擇、事件聚合、事件處理[11]3個步驟的執行順序分為標準化引擎、事件語義分析引擎及復雜事件處理引擎(見
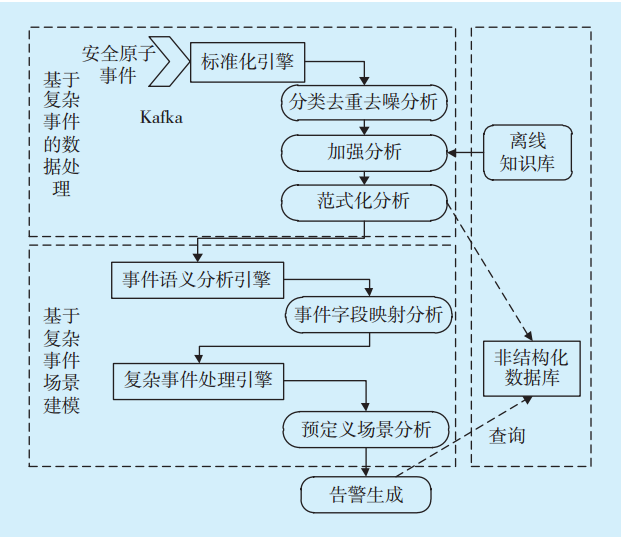 圖2 安全數據關聯分析模塊組成Fig.2 Security data association analysis module
圖2 安全數據關聯分析模塊組成Fig.2 Security data association analysis module
1.2.1 標準化引擎
標準化引擎是對安全數據的過濾、分類、加強及范式化等數據分析工作,實現事件流的主題去重去噪分析、加強分析及范式化分析。該引擎是事件流的標準化分析環節的引擎,業務邏輯是依據不同數據的特性預置的,不需要人工自定義規則,不必結合Esper技術使用EPL語句進行處理,利用Storm框架的高吞吐率,采用Storm的技術架構[12],加快事件流的處理速度。Storm采用實時計算的圖狀結構,圖在Storm中成為拓撲。每個拓撲提交給集群,由集群中的主控節點分發代碼,將任務分配給工作節點執行。一個拓撲中包括spout和bolt 2種角色,其中spout發送消息,負責將數據流以tuple元組的形式發送出去;bolt則負責轉換這些數據流,在bolt中可以完成計算、過濾等操作,bolt自身也可以隨機將數據發送給其他bolt。由spout發射出的tuple是不可變數組,對應著固定的鍵值對。Storm框架如
所示。
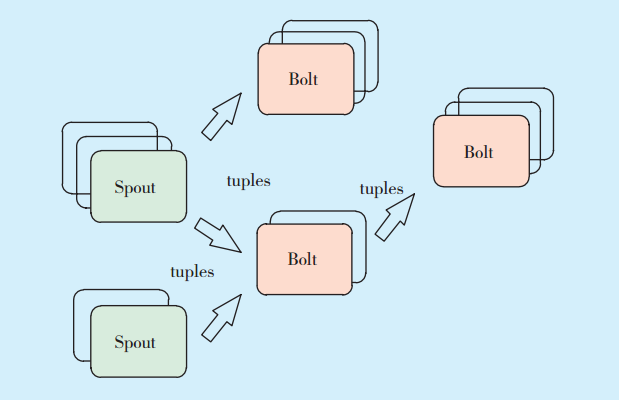 圖3 Storm框架Fig.3 Storm framework
圖3 Storm框架Fig.3 Storm framework
1)分類去重去噪分析
分類去重去噪是對事件流的第一重選擇。
①數據主題分類:根據與數據采集層約定的自定義數據類型主題關鍵詞,將數據分為網絡設備數據、安全設備數據、主機設備數據、終端設備數據、應用設備數據、網絡流數據及情報類數據七大類,并解析數據的分隔符號,將事件流中的data進一步拆分具體屬性特征。
②去重:去重是對分完類且具有具體屬性特征的安全事件流的去重,依據每條日志的MD5值進行計算后,MD5值一致的即為重復數據,僅保留一條有效的,否則會造成數據的冗余。
③去噪:去噪是對已經過去重后的事件流中的“噪點”數據進行修飾,由于事件流中數據類型各異,且來自不同廠商、設備和系統,故數據中包含不符合規范的數據項在所難免,去噪就是對這類數據包括標點符號、特殊符號等噪聲的“消噪”處理,并最大程度還原有意義屬性,不能還原的“臟數據”剔除。
2)加強分析
加強分析是依據業務的要求,將已經過去重去噪的事件流關聯離線的知識庫數據,加強每條事件流的關聯信息,包括IP所在地域、經緯度、資產名稱、責任人等屬性信息。
3)范式化分析
范式化將經過以上2步分析處理的事件流再標準化,只保留符合預定義的格式規范的數據,用于后續事件的語義分析及復雜事件處理。
1.2.2 事件語義分析引擎
事件語義分析引擎即將前一步的標準化后的分析字段進行字段映射。這里的語義是指需要分析的行為模式關聯語義,即按照規范化事件流之間的關聯模式進行分析的語義。事件流語義分析引擎僅進行事件字段映射。
事件字段映射用于提取需要分析的事件流中的關鍵語義,關鍵語義以<Key,Value>鍵值對形式存在,為事件流生成告警的重要屬性字段的集合。
1.2.3 復雜事件處理引擎
復雜事件處理引擎參考CEP的通用處理框架[13](見
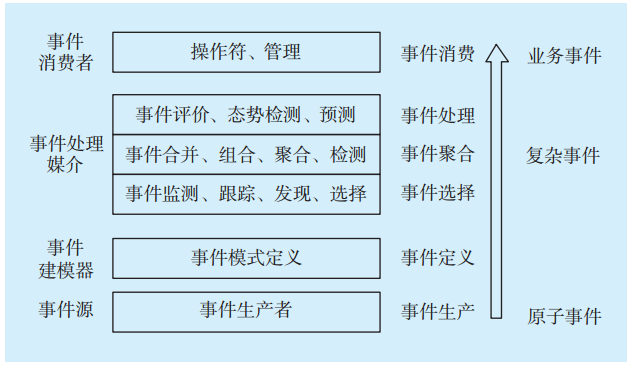 圖4 CEP處理框架Fig.4 CEP processing framework
圖4 CEP處理框架Fig.4 CEP processing framework
CEP處理框架反映的是原子事件進入事件處理引擎后通過一系列的操作,生成復雜事件直至最終事件的流程。復雜事件處理主要負責實時事件流的處理及不同事件流實時關聯分析。
事件輸入來源包括前一步事件流語義分析后的結果,數據覆蓋全面、實時;在事件處理部分,事件建模器中的模型分為預定義場景分析及可視化交互用戶模型自定義分析。在自定義業務規則上使用熱切換實現新建規則。在用戶GUI配置完規則后,實現快速重啟Esper引擎,該引擎依據自定義與否分為預定義場景分析和可視化交互分析。
1.2.4 實時關聯分析算法
在傳統技術架構下,關聯分析算法往往需要從離線的非結構化數據集上執行分析,難以對大量、嘈雜的數據進行融合關聯分析,形成實時全局可視化安全態勢,因此本平臺在Storm等流式計算框架基礎上,結合CEP以及Apriori算法[14],通過數據內存實時分析、海量安全信息實時監控與關聯分析,及時發現安全異常行為。
Apriori算法主要分為2個步驟:第一步對基礎數據進行迭代,檢索出數據中頻繁的項集,其中頻繁的閾值預先設定。第二步首先找出頻繁項集-1,記為L1;然后利用L1來生成候選項集C2,對C2中的項進行判斷挖掘出L2,即頻繁項集-2,其中候選頻繁項集不斷如此循環直到無法發現更多的頻繁項集-
在基礎的Apriori算法中,每一步產生候選項集時循環產生的組合較多,沒有排除冗余元素,其次在數據增多的情況下,對計算機的I/O開銷成幾何倍數增加,因此做出一些改進,將每個項集生成hash值,通過和最小支持計數相比,先淘汰一部分項集。
1.3 告警生成模塊
在事件流經過基于復雜事件處理的數據關聯分析后,將生成的告警存儲在告警生成模塊的關系型MySQL數據庫中[15],并通過數據總線為應用層的使用人員提供統一服務,供不同角色人員進行監控、處置等操作。
1.4 應用場景算例分析與設計
依照基于復雜事件處理的大數據安全關聯分析模型的設計,選取“郵件賬號異常登錄場景”進行算例分析。該場景為:依據采集的海量日志,對企業內部郵件賬號異常登錄的行為進行識別,滿

責任編輯:售電衡衡
-

權威發布 | 新能源汽車產業頂層設計落地:鼓勵“光儲充放”,有序推進氫燃料供給體系建設
2020-11-03新能源,汽車,產業,設計 -

中國自主研制的“人造太陽”重力支撐設備正式啟運
2020-09-14核聚變,ITER,核電 -

探索 | 既耗能又可供能的數據中心 打造融合型綜合能源系統
2020-06-16綜合能源服務,新能源消納,能源互聯網
-
新基建助推 數據中心建設將迎爆發期
2020-06-16數據中心,能源互聯網,電力新基建 -

泛在電力物聯網建設下看電網企業數據變現之路
2019-11-12泛在電力物聯網 -

泛在電力物聯網建設典型實踐案例
2019-10-15泛在電力物聯網案例



-
權威發布 | 新能源汽車產業頂層設計落地:鼓勵“光儲充放”,有序推進氫燃料供給體系建設
2020-11-03新能源,汽車,產業,設計 -
中國自主研制的“人造太陽”重力支撐設備正式啟運
2020-09-14核聚變,ITER,核電 -

能源革命和電改政策紅利將長期助力儲能行業發展
-
探索 | 既耗能又可供能的數據中心 打造融合型綜合能源系統
2020-06-16綜合能源服務,新能源消納,能源互聯網 -

5G新基建助力智能電網發展
2020-06-125G,智能電網,配電網 -

從智能電網到智能城市