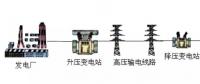
2018年,大數(shù)據(jù)、云計算和AI將如何攪動市場?
2018年,熱門技術(shù)仍將繼續(xù)享受萬眾矚目,但也發(fā)生了一些變化。
過去的一年,提起新技術(shù),可以說不勝枚舉:云計算的使用速度超過了分析師的預測,并衍生了一些新技術(shù);人工智能被引入到日常生活的方方面面;物聯(lián)網(wǎng)和邊緣計算應(yīng)運而生;大量的云計算技術(shù)變?yōu)楝F(xiàn)實,如Kubernetes,serverless,以及云數(shù)據(jù)庫等。新的一年是時候分析這些趨勢的落地情況,并一下預測2018年科技領(lǐng)域的趨勢。
誠然,大家都喜歡新技術(shù),但一般的企業(yè)主、IT買家和軟件開發(fā)人員對這一巨大的創(chuàng)新并不太了解,而且不知道如何將其轉(zhuǎn)化為商業(yè)價值。為此,我們探討了一些可能在2018年會看到的趨勢,其重點將是如何使新技術(shù)變得更容易和可消費。
一切趨向serveless化
亞馬遜和其他云服務(wù)提供商正在競相獲取和保持其市場份額,因此他們不斷提高跨服務(wù)集成的水平,以提高開發(fā)人員的生產(chǎn)力,并加強客戶粘性程度。例如亞馬遜在最近的AWS Re:Invent大會上推出了新的數(shù)據(jù)庫服務(wù)產(chǎn)品,并全面集成了人工智能圖書館和其他工具。同時,它也開始區(qū)分不同形式的serverless:AWS Lambda是關(guān)于serverless功能,而AWS Aurora和Athena則是關(guān)于serverless數(shù)據(jù)庫,從而將serverless的定義擴展到任何可隱藏底層服務(wù)器的領(lǐng)域。據(jù)推測,現(xiàn)在有更多的云服務(wù)將能夠通過該定義稱自己為“serverless”了。
2018年,我們將看到云供應(yīng)商會更加重視并進一步整合個性化服務(wù)。他們還將關(guān)注與人工智能、數(shù)據(jù)管理和serverless相關(guān)的服務(wù)。這些解決方案將使開發(fā)人員和操作人員的工作更簡單,并隱藏其固有的復雜性。然而,他們確實帶來了更大的用戶粘性風險。
在2017年,Kubernetes作為容器編配的標準吸引了所有的云供應(yīng)商。2018年,我們將看到越來越多的廠商將在Kubernetes上建立的服務(wù),該服務(wù)可以為私有云產(chǎn)品提供多云服務(wù)。Iguazio的Nuclio就是這樣一個開放和多云服務(wù)器平臺中一個很好的例子,Red Hat的Openshift 多云 PaaS也是如此。
智能邊緣vs私有云
云服務(wù)確保了企業(yè)所需的業(yè)務(wù)敏捷性,這對開發(fā)數(shù)據(jù)驅(qū)動的應(yīng)用程序來說是非常有必要的,無論是在初創(chuàng)公司還是在大型企業(yè)中。挑戰(zhàn)在于,企業(yè)不能忽略數(shù)據(jù)的引力,因為許多數(shù)據(jù)源仍然處在邊緣領(lǐng)域。5G帶寬,延遲,新法規(guī)如GDPR,以及更多的因素強制企業(yè)將計算和存儲放在離數(shù)據(jù)源更近的地方。
今天的公有云模型是服務(wù)用戶消費的,因此開發(fā)人員和用戶可以繞過 IT,引入一些serveless的功能,使用自助服務(wù)數(shù)據(jù)庫,甚至可以將視頻上傳到云服務(wù)中,并將其轉(zhuǎn)換為所需的語言。但是,當使用本地替代方案時,你必須自己構(gòu)建服務(wù),而技術(shù)棧的發(fā)展速度非常之快,所以IT團隊幾乎不可能構(gòu)建出可以與云替代方案相比較的現(xiàn)代化服務(wù)。
標簽為“私有云”的IT供應(yīng)商解決方案與真正的云完全不同,因為它們關(guān)注的是自動化IT操作。它們沒有提供更高級別的面向用戶和開發(fā)人員的服務(wù)——它最終是將幾十個單獨的開源或商業(yè)軟件包組合起來,添加常見的安全層、日志記錄和配置管理等,這也為云供應(yīng)商和新公司進入邊緣領(lǐng)域提供了機會。
2017年,微軟首席執(zhí)行官Satya Nadella越來越關(guān)注他所謂的“智能邊緣”。微軟推出了Azure Stack,這是Azure云的一個迷你版本,不幸的是,這只包含微軟在云計算中提供的一小部分服務(wù)。之后,亞馬遜也開始推出名為“Snowball Edge”的邊緣設(shè)備。
智能邊緣不是私有云。它提供了與公有云相同的服務(wù)和操作模型,但它是本地訪問的,并且在許多情況下是由一個中心云操作和維護的,就像操作人員管理我們的有線機頂盒一樣。
在2018年,傳統(tǒng)的私有云市場將會逐漸萎縮,同時智能邊緣的勢頭將會增長。云提供商將增加邊緣產(chǎn)品,新公司將進入該領(lǐng)域,在某些情況下,通過集成產(chǎn)品到特定的垂直應(yīng)用程序或用例上。
從純技術(shù)到具有嵌入式特征和垂直堆棧的AI
2017年,人工智能和機器學習技術(shù)快速興起,盡管獲得了大肆宣傳,但實際上主要是被亞馬遜、谷歌和Facebook等市場領(lǐng)先的網(wǎng)絡(luò)公司所使用。雖然對于一般企業(yè)來說,人工智能是舉足輕重的,但是就大多數(shù)企業(yè)而言,的確還沒有理由去雇傭那些所謂的數(shù)據(jù)科學家,或者從頭開始構(gòu)建和培訓人工智能模型。
我們可以看到Salesforce這樣的公司是如何利用其所承載的大量客戶數(shù)據(jù)將人工智能構(gòu)建到平臺的。其他公司也在沿著這條道路將人工智能嵌入到產(chǎn)品中。與此同時,針對特定行業(yè)和垂直領(lǐng)域的AI軟件解決方案,比如市場營銷、零售、醫(yī)療保健、金融和安全也將不斷涌現(xiàn)。用戶不需要知道神經(jīng)網(wǎng)絡(luò)的內(nèi)部結(jié)構(gòu)或這些解決方案中的回歸算法。相反,它們將提供數(shù)據(jù)和一組參數(shù),并得到可以在應(yīng)用程序中使用的AI模型。
人工智能仍然是一個非常新的領(lǐng)域,有許多重疊的產(chǎn)品,而且沒有標準化。如果你在學習階段使用了像TensorFlow、Spark、H2O和Python這樣的框架,那么你將需要使用相同的方法來運行推斷部分。2018年,開放和跨平臺的人工智能模型將被定義。此外,我們還將看到更多的解決方案,這些解決方案可以自動化構(gòu)建、培訓和部署人工智能的過程,就像新引入的AWS Sage Maker一樣。
大數(shù)據(jù)到連續(xù)數(shù)據(jù)
在過去的幾年中,企業(yè)已經(jīng)開始開發(fā)由主要IT技術(shù)驅(qū)動的大數(shù)據(jù)應(yīng)用。它的目標是收集、管理和集中分析業(yè)務(wù)數(shù)據(jù)和日志,以便將來應(yīng)用。數(shù)據(jù)收集在Hadoop集群和數(shù)據(jù)倉庫解決方案中,然后由一組數(shù)據(jù)科學家使用,他們運行并進行批量處理作業(yè)并生成一些報告或儀表盤。然而,根據(jù)所有知名分析師的偵測,這種方法已經(jīng)被證明是失敗的,據(jù)Gartner的數(shù)據(jù)顯示有70%的公司沒有看到任何投資回報率。所以,數(shù)據(jù)必須是可操作的,才能從中獲得ROI。它必須集成到業(yè)務(wù)流程中,并從新的數(shù)據(jù)中派生出來,就像我們在目標廣告和谷歌、Facebook的關(guān)鍵詞鎖定中看到的一樣。
數(shù)據(jù)洞察必須嵌入到現(xiàn)代商業(yè)應(yīng)用中。例如,訪問一個網(wǎng)站或使用聊天機器人的客戶需要根據(jù)其最近的活動或個人簡介來獲得針對目標內(nèi)容的即時響應(yīng)。從物聯(lián)網(wǎng)或移動設(shè)備收集到的傳感數(shù)據(jù)連續(xù)不斷地流動,需要立即采取行動來驅(qū)動警報、檢測安全違規(guī)、提供預測性維護,或啟用糾正措施。用于監(jiān)視和國家機密的可視化數(shù)據(jù)必須實時查看;零售商還利用它來分析銷售數(shù)據(jù),如庫存狀況、客戶偏好以及基于觀察客戶活動獲得的實時建議。數(shù)據(jù)和實時分析通過自動化的過程降低了業(yè)務(wù)成本。汽車正變得越來越自動化。電話推銷員和助手被機器人取代。艦隊、卡車、出租車司機或技術(shù)人員由人工智能和事件驅(qū)動的邏輯統(tǒng)一編排,以最大限度地利用資源。
所有這些都已經(jīng)在2017年發(fā)生了。
像Hadoop和數(shù)據(jù)倉庫這樣的技術(shù)十年前就已經(jīng)出現(xiàn)了,比人工智能、流處理、內(nèi)存或閃存技術(shù)出現(xiàn)的早。企業(yè)發(fā)現(xiàn),構(gòu)建數(shù)據(jù)湖的價值是有限的,因為他們可以通過使用更簡單的云技術(shù)來進行數(shù)據(jù)挖掘。而關(guān)注的焦點也從主要是收集數(shù)據(jù)轉(zhuǎn)到持續(xù)使用數(shù)據(jù),這一領(lǐng)域的技術(shù)主要集中在收集靜止和以IT驅(qū)動過程中的數(shù)據(jù),而非流動的數(shù)據(jù)。
2018年,人們將看到從大數(shù)據(jù)向快速、連續(xù)數(shù)據(jù)驅(qū)動型應(yīng)用程序的持續(xù)轉(zhuǎn)變。數(shù)據(jù)將被各種各樣的來源不斷地抓取。與預先學習或不斷學習的人工智能模型相比,它將在實時的情況下被語境化、豐富和聚合,這樣它就可以立即對用戶產(chǎn)生響應(yīng),驅(qū)動操作,并在實時的交互式儀表盤中呈現(xiàn)。
開發(fā)人員將使用預先打包的云產(chǎn)品,或者使用相關(guān)的原生云服務(wù)集成解決方案。在企業(yè)中,焦點將從IT轉(zhuǎn)移到業(yè)務(wù)部門和應(yīng)用程序開發(fā)人員,他們將在現(xiàn)有的業(yè)務(wù)邏輯、web門戶和日常客戶交互中嵌入數(shù)據(jù)驅(qū)動的決策。
總之,2018年,我們將看到這些變化:
1、智能邊緣領(lǐng)域?qū)鲩L,傳統(tǒng)的私有云市場將會萎縮。
2、針對特定行業(yè)和垂直領(lǐng)域的人工智能軟件解決方案,AI模型將開始開放和跨平臺。
3、快速的數(shù)據(jù)、連續(xù)的應(yīng)用程序和云服務(wù)將取代大數(shù)據(jù)和Hadoop。
4、云服務(wù)將變得更易用,從而增加其與傳統(tǒng)和私有云解決方案之間的差距。
最后,企業(yè)請準備好帶上鐐銬,被更多的用戶鎖定吧!
官方微信售電那點事兒")
責任編輯:馬麗芳
- 相關(guān)閱讀
- 泛在電力物聯(lián)網(wǎng)
- 電動汽車
- 儲能技術(shù)
- 智能電網(wǎng)
- 電力通信
- 電力軟件
- 高壓技術(shù)
-

權(quán)威發(fā)布 | 新能源汽車產(chǎn)業(yè)頂層設(shè)計落地:鼓勵“光儲充放”,有序推進氫燃料供給體系建設(shè)
2020-11-03新能源,汽車,產(chǎn)業(yè),設(shè)計 -

中國自主研制的“人造太陽”重力支撐設(shè)備正式啟運
2020-09-14核聚變,ITER,核電 -

探索 | 既耗能又可供能的數(shù)據(jù)中心 打造融合型綜合能源系統(tǒng)
2020-06-16綜合能源服務(wù),新能源消納,能源互聯(lián)網(wǎng)
-
新基建助推 數(shù)據(jù)中心建設(shè)將迎爆發(fā)期
2020-06-16數(shù)據(jù)中心,能源互聯(lián)網(wǎng),電力新基建 -

泛在電力物聯(lián)網(wǎng)建設(shè)下看電網(wǎng)企業(yè)數(shù)據(jù)變現(xiàn)之路
2019-11-12泛在電力物聯(lián)網(wǎng) -

泛在電力物聯(lián)網(wǎng)建設(shè)典型實踐案例
2019-10-15泛在電力物聯(lián)網(wǎng)案例
-

新基建之充電樁“火”了 想進這個行業(yè)要“心里有底”
2020-06-16充電樁,充電基礎(chǔ)設(shè)施,電力新基建 -

燃料電池汽車駛?cè)雽こ0傩占疫€要多久?
-

備戰(zhàn)全面電動化 多部委及央企“定調(diào)”充電樁配套節(jié)奏
-
權(quán)威發(fā)布 | 新能源汽車產(chǎn)業(yè)頂層設(shè)計落地:鼓勵“光儲充放”,有序推進氫燃料供給體系建設(shè)
2020-11-03新能源,汽車,產(chǎn)業(yè),設(shè)計 -
中國自主研制的“人造太陽”重力支撐設(shè)備正式啟運
2020-09-14核聚變,ITER,核電 -

能源革命和電改政策紅利將長期助力儲能行業(yè)發(fā)展
-
探索 | 既耗能又可供能的數(shù)據(jù)中心 打造融合型綜合能源系統(tǒng)
2020-06-16綜合能源服務(wù),新能源消納,能源互聯(lián)網(wǎng) -

5G新基建助力智能電網(wǎng)發(fā)展
2020-06-125G,智能電網(wǎng),配電網(wǎng) -

從智能電網(wǎng)到智能城市