電力通信大數據并行化聚類算法研究
確度均高于k-medoids并行化算法和DBSCAN并行化算法,并且在處理較大數量級的數據集時,本文算法準確度更占優勢。不同數據集上各算法的執行時間如圖2。
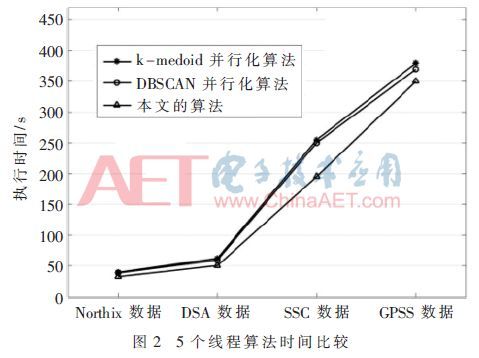
根據圖2,隨著數據量的增大,三種算法執行效率差異逐漸增大,本文算法性能明顯優于k-medoids并行性算法和DBSCAN并行算法。接著對三個算法使用7個線程時的執行時間進行比較,如圖3所示。
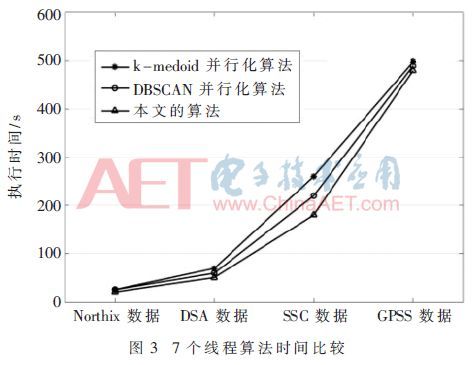
從圖3中可以看出,使用7個線程在1 000、5 000、10 000數據級時,本文算法執行時間明顯優于其他兩個算法。
3.3 實驗小結
仿真實驗可知,在同一線程數時,本文算法比對比算法聚類準確率高,執行時間短;在線程數增加時,本文算法執行時間顯著降低;隨著數據量的增長,本文算法在保證更高準確度的基礎上,執行時間優勢逐漸凸顯。
4 結論
本文針對電力通信數據的聚類處理問題,提出基于密度的聚類思想對k-medoids算法初始點的選取策略進行優化,并利用MapReduce編程框架實現了算法的并行化處理。通過仿真實驗表明本文提出的優化算法可行有效,并具有較好的執行效率。在接下來的研究中可以考慮線程數小于聚類數時的優化分配策略,進一步提高算法性能。
參考文獻
[1] 蔡永強,陳平華,李惠.基于云計算平臺的并行DBSCAN算法[J].廣東工業大學學報,2016,33(1):51-56.
[2] PARK H S,JUN C H.A simple and fast algorithm for k-medoids clustering[J].Expert System with Applications,2009,36(2):3336-3341.
[3] 趙燁,黃澤君.蟻群K-medoids融合的聚類算法[J].電子測量與儀器學報,2012,26(9):800-804.
[4] 馬菁,謝娟英.基于粒計算的k-medoids聚類算法[J].計算機應用,2012,32(7):1973-1977.
[5] 吳景嵐,朱文興.基于k中心點的迭代局部搜索聚類算法[J].計算機研究與發展,2004,41(Z):246-252.
[6] Jiang Yaobin,Zhang Jiongmin.Parallel k-medoids clustering algorithm based on Hadoop[C].Proceedings of the IEEE International Conference on Software Engineering and Service Sciences,2014:649-651.
[7] 孫勝,王元珍.基于核的自適應k-medoid聚類[J].計算機工程與設計,2009,30(3):674-677.
[8] 馬曉慧.一種改進的可并行的K-medoids聚類算法[J].智能計算機與應用,2015:874-876.
作者信息:
曾 瑛,李星南,劉新展
(廣東電網公司 廣東電網電力調度控制中心,廣東 廣州510600)

責任編輯:售電衡衡