深度強化學(xué)習(xí)是什么:AI與深度學(xué)習(xí)的下一代發(fā)展方向
強化學(xué)習(xí)非常適合實現(xiàn)自主決策,相比之下監(jiān)督學(xué)習(xí)與無監(jiān)督學(xué)習(xí)技術(shù)則無法獨立完成此項工作。強化學(xué)習(xí)在人工智能領(lǐng)域長久以來一直扮演著小眾性角色。然而,過去幾年以來,強化學(xué)習(xí)正越來越多地在各類AI項目當(dāng)中發(fā)揮令人矚目的作用。其最突出的應(yīng)用平臺正是在計算代理的環(huán)境背景性決策場景當(dāng)中,負(fù)責(zé)判斷最佳行動。
憑借著試錯法來最大程度提升算法報酬函數(shù),強化學(xué)習(xí)得以在IT運營管理、能源、醫(yī)療衛(wèi)生、同類型、金融、交通以及貿(mào)易等領(lǐng)域構(gòu)建起大量自適應(yīng)性控制與多代理自動化應(yīng)用。其可負(fù)責(zé)對傳統(tǒng)重點領(lǐng)域(機器人、游戲以及模擬)的AI方案進行訓(xùn)練,并有能力在邊緣分析、自然語言處理、機器翻譯、計算機視覺以及數(shù)字化助手方面帶來新一代AI解決方案。

強化學(xué)習(xí)亦成為物聯(lián)網(wǎng)自主邊緣應(yīng)用發(fā)展的前提性基礎(chǔ)。在工業(yè)、交通運輸、醫(yī)療衛(wèi)生以及消費者應(yīng)用等方面,大部分邊緣應(yīng)用的開發(fā)工作皆需要構(gòu)建AI驅(qū)動型機器人,從而在動態(tài)環(huán)境之下根據(jù)不同情境信息以自主方式完成操作。
強化學(xué)習(xí)的工作原理
在這樣的應(yīng)用領(lǐng)域當(dāng)中,邊緣裝置當(dāng)中的AI大腦必須依賴于強化學(xué)習(xí)技術(shù); 更具體地講,其必須有能力在缺少預(yù)置“基于真實”的訓(xùn)練數(shù)據(jù)集的前提下,最大程度積累報酬函數(shù)——例如根據(jù)規(guī)范當(dāng)中包含的一組標(biāo)準(zhǔn)找到問題解決方法。這種作法與其它類型的人工智能學(xué)習(xí)方式——例如監(jiān)督學(xué)習(xí)(立足真實數(shù)據(jù)最大程度降低算法丟失函數(shù))以及無監(jiān)督學(xué)習(xí)(立足各數(shù)據(jù)點最大程度降低距離函數(shù))——正好相反。
然而,AI學(xué)習(xí)方法之間并不一定必須彼此孤立。AI發(fā)展趨勢當(dāng)中最值得關(guān)注的一點在于,強化學(xué)習(xí)正在各類更為先進的應(yīng)用當(dāng)中與監(jiān)督及無監(jiān)督學(xué)習(xí)相融合。AI開發(fā)者們努力將這些方法整合至應(yīng)用程序當(dāng)中,旨在使其實現(xiàn)單一學(xué)習(xí)方法也不足以達(dá)到的新高度。
舉例來說,在不具備標(biāo)記訓(xùn)練數(shù)據(jù)的情況下,監(jiān)督學(xué)習(xí)本身無法起效——這一點在自動駕駛應(yīng)用當(dāng)中體現(xiàn)得尤為顯著。由于每個瞬時環(huán)境情況基本上獨立存在且未經(jīng)預(yù)先標(biāo)記,學(xué)習(xí)方法必須自行找到解決辦法。同樣的,無監(jiān)督學(xué)習(xí)(利用聚類分析來檢測傳感器源以及其它復(fù)雜未標(biāo)記數(shù)據(jù)中的模式)也無法在現(xiàn)實世界當(dāng)中的決策場景內(nèi),準(zhǔn)確識別智能端點并采取最佳操作。
深度強化學(xué)習(xí)是什么
接下來是深度強化學(xué)習(xí),這種領(lǐng)先技術(shù)當(dāng)中的自主代理利用強化學(xué)習(xí)的試錯算法與累加報酬函數(shù)以加速神經(jīng)網(wǎng)絡(luò)設(shè)計。這些設(shè)計能夠極大支持各類依賴于監(jiān)督與/或無監(jiān)督學(xué)習(xí)的AI應(yīng)用程序。
深度強化學(xué)習(xí)已經(jīng)成為AI開發(fā)以及訓(xùn)練管道當(dāng)中的核心關(guān)注區(qū)域。其利用強化學(xué)習(xí)驅(qū)動代理以快速探索各類架構(gòu)、節(jié)點類型、連接、超參數(shù)設(shè)置以及深度學(xué)習(xí)、機器學(xué)習(xí)乃至其它AI模型,并對這些供設(shè)計人員使用的選項進行相關(guān)效能權(quán)衡。
舉例來說,研究人員可利用深度強化學(xué)習(xí)從無數(shù)深度學(xué)習(xí)卷積神經(jīng)網(wǎng)絡(luò)(簡稱CNN)架構(gòu)當(dāng)中快速確定最適合當(dāng)前特征工程、計算機視覺以及圖像分類任務(wù)的選項。由深度強化學(xué)習(xí)提供的結(jié)果可供AI工具用于自動生成最優(yōu)CNN,并配合TensorFlow、MXNet或者PyTorch等深度學(xué)習(xí)開發(fā)工具完成具體任務(wù)。
在這方面,強化學(xué)習(xí)開發(fā)與訓(xùn)練開放框架的持續(xù)涌現(xiàn)無疑令人振奮。若您希望深入了解強化學(xué)習(xí),那么以下強化學(xué)習(xí)框架無疑值得關(guān)注——通過運用這些框架并對其加以擴展,您將能夠?qū)⑵渑cTensorFlow以及其它得到廣泛應(yīng)用的深度學(xué)習(xí)與機器學(xué)習(xí)建模工具進行對接:
強化學(xué)習(xí)框架
具體作用以及獲取方式
TensorFlow Agents:TensorFlow Agents 提供多種工具,可通過強化學(xué)習(xí)實現(xiàn)各類智能應(yīng)用程序的構(gòu)建與訓(xùn)練。作為TensorFlow項目的擴展方案,這套框架能夠?qū)poenAI Gym接口擴展至多個并行環(huán)境,并允許各代理立足TensorFlow之內(nèi)實現(xiàn)以執(zhí)行批量計算。其面向OpoenAI Gy環(huán)境的批量化接口可與TensorFlow實現(xiàn)全面集成,從而高效執(zhí)行各類算法。該框架還結(jié)合有BatchPPO,一套經(jīng)過優(yōu)化的近端策略優(yōu)化算法實現(xiàn)方案。其核心組件包括一個環(huán)境打包器,用于在外部過程中構(gòu)建OpenAI Gym環(huán)境; 一套批量集成,用于實現(xiàn)TensorFlow圖步并以強化學(xué)習(xí)運算的方式重置函數(shù); 外加用于將TensorFlow圖形批處理流程與強化學(xué)習(xí)算法納入訓(xùn)練特內(nèi)單一卻步的組件。
Ray RLLib:RLLib 提供一套基于任務(wù)的靈活編程模式,可用于構(gòu)建基于代理且面向多種應(yīng)用場景的強化學(xué)習(xí)應(yīng)用程序。RLLib由伯克利大學(xué)開發(fā),目前已經(jīng)迎來版本2,其立足Ray實現(xiàn)運行。Ray是一套靈活且高性能的分布式執(zhí)行框架。值得一提的是,RLLib開發(fā)者團隊中的一位成員曾經(jīng)擔(dān)任Apache Spark的主要締造者職務(wù)。
RLLib 可立足TensorFlow與PyTorch框架之內(nèi)起效,能夠?qū)崿F(xiàn)不同算法間的模型共享,并可與Ray Tune超參數(shù)調(diào)整工具進行集成。該框架結(jié)合有一套可組合且可擴展的標(biāo)準(zhǔn)強化學(xué)習(xí)組件庫。各個RLLib組件能夠在分布式應(yīng)用程序當(dāng)中實現(xiàn)并行化、擴展、組合與復(fù)用。
RLLib當(dāng)中包含三種強化學(xué)習(xí)算法——近端策略優(yōu)化(簡稱PPO)、異步優(yōu)勢Actor-Critic(簡稱A3C)以及Deep Q Networks(簡稱DQN),三者皆可運行在任意OpenAI Gym Markov決策流程當(dāng)中。其還為各類新算法的開發(fā)工作提供可擴展原語,用于將RLLib應(yīng)用于新問題的Python API、一套代理超參數(shù)設(shè)置庫以及多種可插拔分布式強化學(xué)習(xí)執(zhí)行策略。其亦支持由用戶創(chuàng)建自定義強化學(xué)習(xí)算法。
Roboschool:Roboschool 提供開源軟件以通過強化學(xué)習(xí)構(gòu)建并訓(xùn)練機器人模擬。其有助于在同一環(huán)境當(dāng)中對多個代理進行強化學(xué)習(xí)訓(xùn)練。通過多方訓(xùn)練機制,您可以訓(xùn)練同一代理分別作為兩方玩家(因此能夠自我對抗)、使用相同算法訓(xùn)練兩套代理,或者設(shè)置兩種算法進行彼此對抗。
Roboschool由OpenAI開發(fā)完成,這一非營利性組織的背后贊助者包括Elon Musk、Sam Altman、Reid Hoffman以及Peter Thiel。其與OpenAI Gym相集成,后者是一套用于開發(fā)及評估強化學(xué)習(xí)算法的開源工具集。OpenAI Gym與TensorFlow、Theano以及其它多種深度學(xué)習(xí)庫相兼容。OpenAI Gym當(dāng)中包含用于數(shù)值計算、游戲以及物理引擎的相關(guān)代碼。
Roboschool基于Bullet物理引擎,這是一套開源許可物理庫,并被其它多種仿真軟件——例如Gazebo與Virtual Robot Experimentation Platform(簡稱V-REP)所廣泛使用。其中包含多種強化學(xué)習(xí)算法,具體以怨報德 異步深度強化學(xué)習(xí)方法、Actor-Critic with Experience Replay、Actor- Critic using Kronecker-Factored Trust Region、深度確定性策略梯度、近端策略優(yōu)化以及信任域策略優(yōu)化等等。
Machine Learning Agents:盡管尚處于beta測試階段,但Unity Technology的Machine Learning Agents已經(jīng)能夠面向游戲、模擬、自動駕駛車輛以及機器人實現(xiàn)智能代理的開發(fā)與強化學(xué)習(xí)訓(xùn)練。ML-Agents支持多種強化學(xué)習(xí)訓(xùn)練場景,具體涉及各類代理、大腦以及報酬機制的配置與彼此交互。該框架的SDK支持單代理與多代理場景,亦支持離散與連續(xù)操作空間。其提供Python API以訪問強化學(xué)習(xí)、神經(jīng)進化以及其它機器學(xué)習(xí)方法。
ML-Agents學(xué)習(xí)環(huán)境包括大量通過與自動化組件(即‘大腦’)交互以實現(xiàn)執(zhí)行的代理。各個代理皆能夠擁有自己的一套獨特狀態(tài)與觀察集,在環(huán)境當(dāng)中執(zhí)行特定操作,并在環(huán)境之內(nèi)接收與事件相關(guān)的獨特報酬。代理的操作由與之對接的大腦決定。每個大腦負(fù)責(zé)定義一項特定狀態(tài)與操作空間,并決定與之相連的各代理應(yīng)采取哪項操作。
除此之外,每個ML-Agents環(huán)境還包含一個獨立“學(xué)院”,用于定義環(huán)境范圍——具體包括引擎配置(訓(xùn)練與推理模式下游戲引擎的速度與渲染質(zhì)量)、幀數(shù)(每個代理作出新決策的間隔當(dāng)中跳過多少引擎步驟)以及全局事件長度(即事件將持續(xù)多長時間)。
在大腦能夠設(shè)定的各類模式當(dāng)中,外部模式最值得一提——其中的操作決策利用TensorFlow或者其它選定的機器學(xué)習(xí)庫制定,且通過開放套接配合ML-Agents的Python API實現(xiàn)通信。同樣的,內(nèi)部模式中的代理操作決策則利用一套通過嵌入TensorFlowSharp代理接入項目的預(yù)訓(xùn)練模型負(fù)責(zé)制定。
Coach:英特爾公司的Nervana Coach是一套開源強化學(xué)習(xí)框架,負(fù)責(zé)對游戲、機器人以及其它基于代理的智能應(yīng)用進行智能代理的建模、訓(xùn)練與評估。
Coach 提供一套模塊化沙箱、可復(fù)用組件以及用于組合新強化學(xué)習(xí)算法并在多種應(yīng)用領(lǐng)域內(nèi)訓(xùn)練新智能應(yīng)用的Python API。該框架利用OpenAI Gym作為主工具,負(fù)責(zé)與不同強化學(xué)習(xí)環(huán)境進行交換。其還支持其它外部擴展,具體包括Roboschool、gym-extensions、PyBullet以及ViZDoom。Coach的環(huán)境打包器允許用戶向其中添加自定義強化學(xué)習(xí)環(huán)境,從而解決其它學(xué)習(xí)問題。
該框架能夠在桌面計算機上高效訓(xùn)練強化學(xué)習(xí)代理,并利用多核CPU處理相關(guān)任務(wù)。其能夠為一部分強化學(xué)習(xí)算法提供單線程與多線程實現(xiàn)能力,包括異步優(yōu)勢Actor-Critic、深度確定性策略梯度、近端策略優(yōu)化、直接未來預(yù)測以及規(guī)范化優(yōu)勢函數(shù)。所有算法皆利用面向英特爾系統(tǒng)作出優(yōu)化的TensorFLow完成,其中部分算法亦適用于英特爾的Neon深度學(xué)習(xí)框架。
Coach 當(dāng)中包含多種強化學(xué)習(xí)代理實現(xiàn)方案,具體包括從單線程實現(xiàn)到多線程實現(xiàn)的轉(zhuǎn)換。其能夠開發(fā)出支持單與多工作程序(同步或異步)強化學(xué)習(xí)實現(xiàn)方法的新代理。此外,其還支持連續(xù)與離散操作空間,以及視覺觀察空間或僅包含原始測量指標(biāo)的觀察空間。
AI開發(fā)者需要掌握的強化學(xué)習(xí)技能
展望未來,AI開發(fā)者們需要盡可能掌握上述框架以及其中所使用的各類強化學(xué)習(xí)算法。此外,您還需要強化自身對于多代理強化學(xué)習(xí)架構(gòu)的理解,因為其中多種框架都大量利用前沿博弈論研究成果。最后,您還需要熟悉深度強化學(xué)習(xí)知識,并借此發(fā)現(xiàn)計算機視覺應(yīng)用程序當(dāng)中所出現(xiàn)的“模糊(fuzzing)”攻擊及相關(guān)安全漏洞。
官方微信售電那點事兒")
責(zé)任編輯:任我行
- 相關(guān)閱讀
- 碳交易
- 節(jié)能環(huán)保
- 電力法律
- 電力金融
- 綠色電力證書
-

碳中和戰(zhàn)略|趙英民副部長致辭全文
2020-10-19碳中和,碳排放,趙英民 -

兩部門:推廣不停電作業(yè)技術(shù) 減少停電時間和停電次數(shù)
2020-09-28獲得電力,供電可靠性,供電企業(yè) -
國家發(fā)改委、國家能源局:推廣不停電作業(yè)技術(shù) 減少停電時間和停電次數(shù)
2020-09-28獲得電力,供電可靠性,供電企業(yè)
-
碳中和戰(zhàn)略|趙英民副部長致辭全文
2020-10-19碳中和,碳排放,趙英民 -

深度報告 | 基于分類監(jiān)管與當(dāng)量協(xié)同的碳市場框架設(shè)計方案
2020-07-21碳市場,碳排放,碳交易 -

碳市場讓重慶能源轉(zhuǎn)型與經(jīng)濟發(fā)展并進
2020-07-21碳市場,碳排放,重慶
-
兩部門:推廣不停電作業(yè)技術(shù) 減少停電時間和停電次數(shù)
2020-09-28獲得電力,供電可靠性,供電企業(yè) -
國家發(fā)改委、國家能源局:推廣不停電作業(yè)技術(shù) 減少停電時間和停電次數(shù)
2020-09-28獲得電力,供電可靠性,供電企業(yè) -
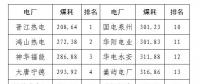
2020年二季度福建省統(tǒng)調(diào)燃煤電廠節(jié)能減排信息披露
2020-07-21火電環(huán)保,燃煤電廠,超低排放
-

四川“專線供電”身陷違法困境
2019-12-16專線供電 -

我國能源替代規(guī)范法律問題研究(上)
2019-10-31能源替代規(guī)范法律 -

區(qū)域鏈結(jié)構(gòu)對于數(shù)據(jù)中心有什么影響?這個影響是好是壞呢!