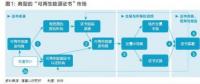
企業如何實現對大數據的處理與分析?
隨著兩化深度融合的持續推進,全面實現業務管理和生產過程的數字化、自動化和智能化是企業持續保持市場競爭力的關鍵。在這一過程中數據
隨著兩化深度融合的持續推進,全面實現業務管理和生產過程的數字化、自動化和智能化是企業持續保持市場競爭力的關鍵。在這一過程中數據必將成為企業的核心資產,對數據的處理、分析和運用將極大的增強企業的核心競爭力。但長期以來,由于數據分析手段和工具的缺乏,大量的業務數據在系統中層層積壓而得不到利用,不但增加了系統運行和維護的壓力,而且不斷的侵蝕有限的企業資金投入。如今,隨著大數據技術及應用逐漸發展成熟,如何實現對大量數據的處理和分析已經成為企業關注的焦點。

對企業而言,由于長期以來已經積累的海量的數據,哪些數據有分析價值?哪些數據可以暫時不用處理?這些都是部署和實施大數據分析平臺之前必須梳理的問題點。以下就企業實施和部署大數據平臺,以及如何實現對大量數據的有效運用提供建議。
第一步:采集數據
對企業而言,不論是新實施的系統還是老舊系統,要實施大數據分析平臺,就需要先弄明白自己到底需要采集哪些數據。因為考慮到數據的采集難度和成本,大數據分析平臺并不是對企業所有的數據都進行采集,而是相關的、有直接或者間接聯系的數據,企業要知道哪些數據是對于戰略性的決策或者一些細節決策有幫助的,分析出來的數據結果是有價值的,這也是考驗一個數據分析員的時刻。比如企業只是想了解產線設備的運行狀態,這時候就只需要對影響產線設備性能的關鍵參數進行采集。再比如,在產品售后服務環節,企業需要了解產品使用狀態、購買群體等信息,這些數據對支撐新產品的研發和市場的預測都有著非常重要的價值。因此,建議企業在進行大數據分析規劃的時候針對一個項目的目標進行精確的分析,比較容易滿足業務的目標。
大數據的采集過程的難點主是并發數高,因為同時有可能會有成千上萬的用戶來進行訪問和操作,比如火車票售票網站和淘寶,它們并發的訪問量在峰值時達到上百萬,所以需要在采集端部署大量數據庫才能支撐。并且如何在這些數據庫之間進行負載均衡和分片也是需要深入的思考問題。
第二步:導入及預處理數據
采集過程只是大數據平臺搭建的第一個環節。當確定了哪些數據需要采集之后,下一步就需要對不同來源的數據進行統一處理。比如在智能工廠里面可能會有視頻監控數據、設備運行數據、物料消耗數據等,這些數據可能是結構化或者非結構化的。這個時候企業需要利用ETL工具將分布的、異構數據源中的數據如關系數據、平面數據文件等抽取到臨時中間層后進行清洗、轉換、集成,將這些來自前端的數據導入到一個集中的大型分布式數據庫或者分布式存儲集群,最后加載到數據倉庫或數據集市中,成為聯機分析處理、數據挖掘的基礎。對于數據源的導入與預處理過程,最大的挑戰主要是導入的數據量大,每秒鐘的導入量經常會達到百兆,甚至千兆級別。
第三步:統計與分析
統計與分析主要利用分布式數據庫,或者分布式計算集群來對存儲于其內的海量數據進行普通的分析和分類匯總等,以滿足大多數常見的分析需求,在這方面,一些實時性需求會用到EMC的GreenPlum、Oracle的Exadata,以及基于MySQL的列式存儲Infobright等,而一些批處理,或者基于半結構化數據的需求可以使用Hadoop.數據的統計分析方法也很多,如假設檢驗、顯著性檢驗、差異分析、相關分析、T檢驗、方差分析、卡方分析、偏相關分析、距離分析、回歸分析、簡單回歸分析、多元回歸分析、逐步回歸、回歸預測與殘差分析、嶺回歸、logistic回歸分析、曲線估計、因子分析、聚類分析、主成分分析、因子分析、快速聚類法與聚類法、判別分析、對應分析、多元對應分析(最優尺度分析)、bootstrap技術等等。在統計與分析這部分,主要特點和挑戰是分析涉及的數據量大,其對系統資源,特別是I/O會有極大的占用。
第四步:價值挖掘
與前面統計和分析過程不同的是,數據挖掘一般沒有什么預先設定好的主題,主要是在現有數據上面進行基于各種算法的計算,從而起到預測的效果,從而實現一些高級別數據分析的需求。比較典型算法有用于聚類的Kmeans、用于統計學習的SVM和用于分類的NaiveBayes,主要使用的工具有Hadoop的Mahout等。該過程的特點和挑戰主要是用于挖掘的算法很復雜,并且計算涉及的數據量和計算量都很大,常用數據挖掘算法都以單線程為主。
總結
為了得到更加精確的結果,在大數據分析的過程要求企業相關的業務規則都是已經確定好的,這些業務規則可以幫助數據分析員評估他們的工作復雜性,對了應對這些數據的復雜性,將數據進行分析得出有價值的結果,才能更好的實施。制定好了相關的業務規則之后,數據分析員需要對這些數據進行分析輸出,因為很多時候,這些數據結果都是為了更好的進行查詢以及用在下一步的決策當中使用,如果項目管理團隊的人員和數據分析員以及相關的業務部門沒有進行很好的溝通,就會導致許多項目需要不斷地重復和重建。最后,由于分析平臺會長期使用,但決策層的需求是變化的,隨著企業的發展,會有很多的新的問題出現,數據分析員的數據分析也要及時的進行更新,現在的很多數據分析軟件創新的主要方面也是關于對數據的需求變化部分,可以保持數據分析結果的持續價值。
對企業而言,由于長期以來已經積累的海量的數據,哪些數據有分析價值?哪些數據可以暫時不用處理?這些都是部署和實施大數據分析平臺之前必須梳理的問題點。以下就企業實施和部署大數據平臺,以及如何實現對大量數據的有效運用提供建議。
第一步:采集數據
對企業而言,不論是新實施的系統還是老舊系統,要實施大數據分析平臺,就需要先弄明白自己到底需要采集哪些數據。因為考慮到數據的采集難度和成本,大數據分析平臺并不是對企業所有的數據都進行采集,而是相關的、有直接或者間接聯系的數據,企業要知道哪些數據是對于戰略性的決策或者一些細節決策有幫助的,分析出來的數據結果是有價值的,這也是考驗一個數據分析員的時刻。比如企業只是想了解產線設備的運行狀態,這時候就只需要對影響產線設備性能的關鍵參數進行采集。再比如,在產品售后服務環節,企業需要了解產品使用狀態、購買群體等信息,這些數據對支撐新產品的研發和市場的預測都有著非常重要的價值。因此,建議企業在進行大數據分析規劃的時候針對一個項目的目標進行精確的分析,比較容易滿足業務的目標。
大數據的采集過程的難點主是并發數高,因為同時有可能會有成千上萬的用戶來進行訪問和操作,比如火車票售票網站和淘寶,它們并發的訪問量在峰值時達到上百萬,所以需要在采集端部署大量數據庫才能支撐。并且如何在這些數據庫之間進行負載均衡和分片也是需要深入的思考問題。
第二步:導入及預處理數據
采集過程只是大數據平臺搭建的第一個環節。當確定了哪些數據需要采集之后,下一步就需要對不同來源的數據進行統一處理。比如在智能工廠里面可能會有視頻監控數據、設備運行數據、物料消耗數據等,這些數據可能是結構化或者非結構化的。這個時候企業需要利用ETL工具將分布的、異構數據源中的數據如關系數據、平面數據文件等抽取到臨時中間層后進行清洗、轉換、集成,將這些來自前端的數據導入到一個集中的大型分布式數據庫或者分布式存儲集群,最后加載到數據倉庫或數據集市中,成為聯機分析處理、數據挖掘的基礎。對于數據源的導入與預處理過程,最大的挑戰主要是導入的數據量大,每秒鐘的導入量經常會達到百兆,甚至千兆級別。
第三步:統計與分析
統計與分析主要利用分布式數據庫,或者分布式計算集群來對存儲于其內的海量數據進行普通的分析和分類匯總等,以滿足大多數常見的分析需求,在這方面,一些實時性需求會用到EMC的GreenPlum、Oracle的Exadata,以及基于MySQL的列式存儲Infobright等,而一些批處理,或者基于半結構化數據的需求可以使用Hadoop.數據的統計分析方法也很多,如假設檢驗、顯著性檢驗、差異分析、相關分析、T檢驗、方差分析、卡方分析、偏相關分析、距離分析、回歸分析、簡單回歸分析、多元回歸分析、逐步回歸、回歸預測與殘差分析、嶺回歸、logistic回歸分析、曲線估計、因子分析、聚類分析、主成分分析、因子分析、快速聚類法與聚類法、判別分析、對應分析、多元對應分析(最優尺度分析)、bootstrap技術等等。在統計與分析這部分,主要特點和挑戰是分析涉及的數據量大,其對系統資源,特別是I/O會有極大的占用。
第四步:價值挖掘
與前面統計和分析過程不同的是,數據挖掘一般沒有什么預先設定好的主題,主要是在現有數據上面進行基于各種算法的計算,從而起到預測的效果,從而實現一些高級別數據分析的需求。比較典型算法有用于聚類的Kmeans、用于統計學習的SVM和用于分類的NaiveBayes,主要使用的工具有Hadoop的Mahout等。該過程的特點和挑戰主要是用于挖掘的算法很復雜,并且計算涉及的數據量和計算量都很大,常用數據挖掘算法都以單線程為主。
總結
為了得到更加精確的結果,在大數據分析的過程要求企業相關的業務規則都是已經確定好的,這些業務規則可以幫助數據分析員評估他們的工作復雜性,對了應對這些數據的復雜性,將數據進行分析得出有價值的結果,才能更好的實施。制定好了相關的業務規則之后,數據分析員需要對這些數據進行分析輸出,因為很多時候,這些數據結果都是為了更好的進行查詢以及用在下一步的決策當中使用,如果項目管理團隊的人員和數據分析員以及相關的業務部門沒有進行很好的溝通,就會導致許多項目需要不斷地重復和重建。最后,由于分析平臺會長期使用,但決策層的需求是變化的,隨著企業的發展,會有很多的新的問題出現,數據分析員的數據分析也要及時的進行更新,現在的很多數據分析軟件創新的主要方面也是關于對數據的需求變化部分,可以保持數據分析結果的持續價值。

責任編輯:售電衡衡
免責聲明:本文僅代表作者個人觀點,與本站無關。其原創性以及文中陳述文字和內容未經本站證實,對本文以及其中全部或者部分內容、文字的真實性、完整性、及時性本站不作任何保證或承諾,請讀者僅作參考,并請自行核實相關內容。
我要收藏
個贊
-

碳中和戰略|趙英民副部長致辭全文
2020-10-19碳中和,碳排放,趙英民 -

兩部門:推廣不停電作業技術 減少停電時間和停電次數
2020-09-28獲得電力,供電可靠性,供電企業 -
國家發改委、國家能源局:推廣不停電作業技術 減少停電時間和停電次數
2020-09-28獲得電力,供電可靠性,供電企業
-
碳中和戰略|趙英民副部長致辭全文
2020-10-19碳中和,碳排放,趙英民 -

深度報告 | 基于分類監管與當量協同的碳市場框架設計方案
2020-07-21碳市場,碳排放,碳交易 -

碳市場讓重慶能源轉型與經濟發展并進
2020-07-21碳市場,碳排放,重慶
-
兩部門:推廣不停電作業技術 減少停電時間和停電次數
2020-09-28獲得電力,供電可靠性,供電企業 -
國家發改委、國家能源局:推廣不停電作業技術 減少停電時間和停電次數
2020-09-28獲得電力,供電可靠性,供電企業 -
2020年二季度福建省統調燃煤電廠節能減排信息披露
2020-07-21火電環保,燃煤電廠,超低排放
-

四川“專線供電”身陷違法困境
2019-12-16專線供電 -

我國能源替代規范法律問題研究(上)
2019-10-31能源替代規范法律 -

區域鏈結構對于數據中心有什么影響?這個影響是好是壞呢!