數(shù)據(jù)庫讀寫分離架構(gòu),為什么我不喜歡
DBA:數(shù)據(jù)量多少?
RD:5000w左右。
DBA:讀寫吞吐量呢?
RD:讀QPS約200,寫QPS約30左右。
上周在公司聽到兩個技術(shù)同學(xué)討論,感覺對讀寫分離解決什么問題沒有弄清楚,有些奔潰。
另,對于互聯(lián)網(wǎng)某些業(yè)務(wù)場景,并不是很喜歡數(shù)據(jù)庫讀寫分離架構(gòu),一些淺見見文末。
一、讀寫分離
什么是數(shù)據(jù)庫讀寫分離?
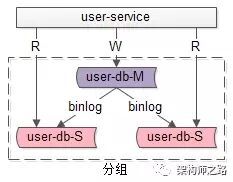
答:一主多從,讀寫分離,主動同步,是一種常見的數(shù)據(jù)庫架構(gòu),一般來說:
-
主庫,提供數(shù)據(jù)庫寫服務(wù)
-
從庫,提供數(shù)據(jù)庫讀服務(wù)
-
主從之間,通過某種機制同步數(shù)據(jù),例如mysql的binlog
一個組從同步集群通常稱為一個“分組”。
分組架構(gòu)究竟解決什么問題?
答:大部分互聯(lián)網(wǎng)業(yè)務(wù)讀多寫少,數(shù)據(jù)庫的讀往往最先成為性能瓶頸,如果希望:
-
線性提升數(shù)據(jù)庫讀性能
-
通過消除讀寫鎖沖突提升數(shù)據(jù)庫寫性能
此時可以使用分組架構(gòu)。
一句話,分組主要解決“數(shù)據(jù)庫讀性能瓶頸”問題,在數(shù)據(jù)庫扛不住讀的時候,通常讀寫分離,通過增加從庫線性提升系統(tǒng)讀性能。
二、水平切分
什么是數(shù)據(jù)庫水平切分?
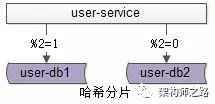
答:水平切分,也是一種常見的數(shù)據(jù)庫架構(gòu),一般來說:
-
每個數(shù)據(jù)庫之間沒有數(shù)據(jù)重合,沒有類似binlog同步的關(guān)聯(lián)
-
所有數(shù)據(jù)并集,組成全部數(shù)據(jù)
-
會用算法,來完成數(shù)據(jù)分割,例如“取模”
一個水平切分集群中的每一個數(shù)據(jù)庫,通常稱為一個“分片”。
水平切分架構(gòu)究竟解決什么問題?
答:大部分互聯(lián)網(wǎng)業(yè)務(wù)數(shù)據(jù)量很大,單庫容量容易成為瓶頸,如果希望:
-
線性降低單庫數(shù)據(jù)容量
-
線性提升數(shù)據(jù)庫寫性能
此時可以使用水平切分架構(gòu)。
一句話總結(jié),水平切分主要解決“數(shù)據(jù)庫數(shù)據(jù)量大”問題,在數(shù)據(jù)庫容量扛不住的時候,通常水平切分。
三、為什么不喜歡讀寫分離
對于互聯(lián)網(wǎng)大數(shù)據(jù)量,高并發(fā)量,高可用要求高,一致性要求高,前端面向用戶的業(yè)務(wù)場景,如果數(shù)據(jù)庫讀寫分離:
-
數(shù)據(jù)庫連接池需要區(qū)分:讀連接池,寫連接池
-
如果要保證讀高可用,讀連接池要實現(xiàn)故障自動轉(zhuǎn)移
-
有潛在的主庫從庫一致性問題
-
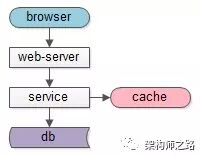
如果面臨的是“讀性能瓶頸”問題,增加緩存可能來得更直接,更容易一點
-
關(guān)于成本,從庫的成本比緩存高不少
-
對于云上的架構(gòu),以阿里云為例,主庫提供高可用服務(wù),從庫不提供高可用服務(wù)
所以,上述業(yè)務(wù)場景下,樓主建議使用緩存架構(gòu)來加強系統(tǒng)讀性能,替代數(shù)據(jù)庫主從分離架構(gòu)。
當然,使用緩存架構(gòu)的潛在問題:如果緩存掛了,流量全部壓到數(shù)據(jù)庫上,數(shù)據(jù)庫會雪崩。不過幸好,云上的緩存一般都提供高可用的服務(wù)。
四、總結(jié)
-
讀寫分離,解決“數(shù)據(jù)庫讀性能瓶頸”問題
-
水平切分,解決“數(shù)據(jù)庫數(shù)據(jù)量大”問題
-
對于互聯(lián)網(wǎng)大數(shù)據(jù)量,高并發(fā)量,高可用要求高,一致性要求高,前端面向用戶的業(yè)務(wù)場景,微服務(wù)緩存架構(gòu),可能比數(shù)據(jù)庫讀寫分離架構(gòu)更合適
官方微信售電那點事兒")
責(zé)任編輯:售電衡衡
- 相關(guān)閱讀
- 碳交易
- 節(jié)能環(huán)保
- 電力法律
- 電力金融
- 綠色電力證書
-

碳中和戰(zhàn)略|趙英民副部長致辭全文
2020-10-19碳中和,碳排放,趙英民 -

兩部門:推廣不停電作業(yè)技術(shù) 減少停電時間和停電次數(shù)
2020-09-28獲得電力,供電可靠性,供電企業(yè) -
國家發(fā)改委、國家能源局:推廣不停電作業(yè)技術(shù) 減少停電時間和停電次數(shù)
2020-09-28獲得電力,供電可靠性,供電企業(yè)
-
碳中和戰(zhàn)略|趙英民副部長致辭全文
2020-10-19碳中和,碳排放,趙英民 -

深度報告 | 基于分類監(jiān)管與當量協(xié)同的碳市場框架設(shè)計方案
2020-07-21碳市場,碳排放,碳交易 -

碳市場讓重慶能源轉(zhuǎn)型與經(jīng)濟發(fā)展并進
2020-07-21碳市場,碳排放,重慶
-
兩部門:推廣不停電作業(yè)技術(shù) 減少停電時間和停電次數(shù)
2020-09-28獲得電力,供電可靠性,供電企業(yè) -
國家發(fā)改委、國家能源局:推廣不停電作業(yè)技術(shù) 減少停電時間和停電次數(shù)
2020-09-28獲得電力,供電可靠性,供電企業(yè) -
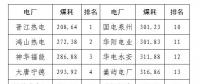
2020年二季度福建省統(tǒng)調(diào)燃煤電廠節(jié)能減排信息披露
2020-07-21火電環(huán)保,燃煤電廠,超低排放
-

四川“專線供電”身陷違法困境
2019-12-16專線供電 -

我國能源替代規(guī)范法律問題研究(上)
2019-10-31能源替代規(guī)范法律 -

區(qū)域鏈結(jié)構(gòu)對于數(shù)據(jù)中心有什么影響?這個影響是好是壞呢!