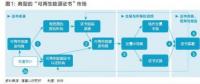
2018年,讓你的數(shù)據(jù)庫(kù)變更快的十個(gè)建議
1、小心設(shè)計(jì)數(shù)據(jù)庫(kù)
第一個(gè)技巧也許看來理所當(dāng)然,但事實(shí)上大部分?jǐn)?shù)據(jù)庫(kù)的問題都來自于設(shè)計(jì)不好的數(shù)據(jù)庫(kù)結(jié)構(gòu)。
譬如我曾經(jīng)遇見過將客戶端信息和支付信息儲(chǔ)存在同一個(gè)數(shù)據(jù)庫(kù)列中的例子。對(duì)于系統(tǒng)和用數(shù)據(jù)庫(kù)的開發(fā)者來說,這很糟糕。
新建數(shù)據(jù)庫(kù)時(shí),應(yīng)當(dāng)將信息儲(chǔ)存在不同的表里,采用標(biāo)準(zhǔn)的命名方式,并采用主鍵。
來源: http://www.simple-talk.com/sql/database-administration/ten-common-database-design-mistakes/
2、清楚你需要優(yōu)化的地方
如果你想優(yōu)化某個(gè)查詢語(yǔ)句,清楚的知道這個(gè)語(yǔ)句的結(jié)果是非常有幫助的。采用 EXPLAIN 語(yǔ)句,你將獲得很多有用的信息,下面來看個(gè)例子:
- EXPLAIN SELECT * FROM ref_table,other_table WHERE ref_table.key_column=other_table.column;
來源: http://dev.mysql.com/doc/refman/5.0/en/using-explain.html
3、最快的查詢語(yǔ)句… 是那些你沒發(fā)送的語(yǔ)句
每次你向數(shù)據(jù)庫(kù)發(fā)送一條語(yǔ)句,你都會(huì)用掉很多服務(wù)器資源。所以在很高流量的網(wǎng)站中,最好的方法是將你的查詢語(yǔ)句緩存起來。
有許多種緩存語(yǔ)句的方法,下面列出了幾個(gè):
AdoDB: AdoDB 是一個(gè) PHP 的數(shù)據(jù)庫(kù)簡(jiǎn)化庫(kù)。使用它,你可以選用不同的數(shù)據(jù)庫(kù)系統(tǒng) (MySQL, PostGreSQL, Interbase 等等),而且它就是為了速度而設(shè)計(jì)的。AdoDB 提供了簡(jiǎn)單但強(qiáng)大的緩存系統(tǒng)。還有,AdoDB 擁有 BSD 許可,你可以在你的項(xiàng)目中免費(fèi)使用它。對(duì)于商業(yè)化的項(xiàng)目,它也有 LGPL 許可。
Memcached:Memcached 是一種分布式內(nèi)存緩存系統(tǒng),它可以減輕數(shù)據(jù)庫(kù)的負(fù)載,來加速基于動(dòng)態(tài)數(shù)據(jù)庫(kù)的網(wǎng)站。
CSQL Cache: CSQL 緩存是一個(gè)開源的數(shù)據(jù)緩存架構(gòu)。我沒有試過它,但它看起來非常的棒。
4、不要 select 你不需要的
獲取想要的數(shù)據(jù),一種非常常見的方式就是采用 * 字符,這會(huì)列出所有的列。
- SELECT * FROM wp_posts;
然而,你應(yīng)該僅列出你需要的列,如下所示。如果在一個(gè)非常小型的網(wǎng)站,譬如,一分鐘一個(gè)用戶訪問,可能沒有什么分別。然而如果像 Cats Who Code 這樣大流量的網(wǎng)站,這就為數(shù)據(jù)庫(kù)省了很多事。
- SELECT title, excerpt, author FROM wp_posts;
5、采用 LIMIT
僅獲得某個(gè)特定行數(shù)的數(shù)據(jù)是非常常見的。譬如博客每頁(yè)只顯示十篇文章。這時(shí),你應(yīng)該使用 LIMIT,來限定你想選定的數(shù)據(jù)的行數(shù)。
如果沒有 LIMIT,表有 100,000 行數(shù)據(jù),你將會(huì)遍歷所有的行數(shù),這對(duì)于服務(wù)器來說是不必要的負(fù)擔(dān)。
- SELECT title, excerpt, author FROM wp_posts LIMIT 10;
6、避免循環(huán)中的查詢
當(dāng)在 PHP 中使用 SQL 時(shí),可以將 SQL 放在循環(huán)語(yǔ)句中。但這么做給你的數(shù)據(jù)庫(kù)增加了負(fù)擔(dān)。
下面的例子說明了 “在循環(huán)語(yǔ)句中嵌套查詢語(yǔ)句” 的問題:
- foreach ($display_order as $id => $ordinal){
- $sql = "UPDATE categories SET display_order = $ordinal WHERE id = $id";
- mysql_query($sql);
- }
你可以這么做:
- UPDATE categories
- SET display_order = CASE id
- WHEN 1 THEN 3
- WHEN 2 THEN 4
- WHEN 3 THEN 5
- END WHERE id IN (1,2,3)
來源: http://www.karlrixon.co.uk/articles/sql/update-multiple-rows-with-different-values-and-a-single-sql-query/
7、采用 join 來替換子查詢
程序員可能會(huì)喜歡用子查詢,甚至濫用。下面的子查詢非常有用:
- SELECT a.id,
- (SELECT MAX(created)
- FROM posts
- WHERE author_id = a.id)
- AS latest_post FROM authors a
雖然子查詢很有用,但 join 語(yǔ)句可以替換它,join 語(yǔ)句執(zhí)行起來更快。
- SELECT a.id, MAX(p.created) AS latest_post
- FROM authors a
- INNER JOIN posts p
- ON (a.id = p.author_id)
- GROUP BY a.id
來源: http://20bits.com/articles/10-tips-for-optimizing-mysql-queries-that-dont-suck/
8、小心使用通配符
通配符非常好用,在搜索數(shù)據(jù)的時(shí)候可以用通配符來代替一個(gè)或多個(gè)字符。我不是說不能用,而是,應(yīng)該小心使用,并且不要使用全詞通配符 (full wildcard),前綴通配符或后置通配符可以完成相同的任務(wù)。
事實(shí)上,在百萬(wàn)數(shù)量級(jí)的數(shù)據(jù)上采用全詞通配符來搜索會(huì)讓你的數(shù)據(jù)庫(kù)當(dāng)機(jī)。
- #Full wildcard
- SELECT * FROM TABLE WHERE COLUMN LIKE '%hello%'; #Postfix wildcard
- SELECT * FROM TABLE WHERE COLUMN LIKE 'hello%'; #Prefix wildcard
- SELECT * FROM TABLE WHERE COLUMN LIKE '%hello';
來源: http://hungred.com/useful-information/ways-optimize-sql-queries/
9、采用 UNION 來代替 OR
下面的例子采用 OR 語(yǔ)句來:
- SELECT * FROM a, b WHERE a.p = b.q or a.x = b.y;
UNION 語(yǔ)句,你可以將 2 個(gè)或更多 select 語(yǔ)句的結(jié)果拼在一起。下面的例子返回的結(jié)果同上面的一樣,但是速度要快些:
- SELECT * FROM a, b WHERE a.p = b.q
- UNION
- SELECT * FROM a, b WHERE a.x = b.y
來源: http://www.bcarter.com/optimsql.htm
10. 使用索引
數(shù)據(jù)庫(kù)索引和你在圖書館中見到的索引類似:能讓你更快速的獲取想要的信息,正如圖書館中的索引能讓讀者更快的找到想要的書一樣。
可以在一個(gè)列上創(chuàng)建索引,也可以在多個(gè)列上創(chuàng)建。索引是一種數(shù)據(jù)結(jié)構(gòu),它將表中的一列或多列的值以特定的順序組織起來。
下面的語(yǔ)句在 Product 表的 Model 列上創(chuàng)建索引。這個(gè)索引的名字叫作 idxModel
- CREATE INDEX idxModel ON Product (Model);
官方微信售電那點(diǎn)事兒")
責(zé)任編輯:售電衡衡
- 相關(guān)閱讀
- 碳交易
- 節(jié)能環(huán)保
- 電力法律
- 電力金融
- 綠色電力證書
-

碳中和戰(zhàn)略|趙英民副部長(zhǎng)致辭全文
2020-10-19碳中和,碳排放,趙英民 -

兩部門:推廣不停電作業(yè)技術(shù) 減少停電時(shí)間和停電次數(shù)
2020-09-28獲得電力,供電可靠性,供電企業(yè) -
國(guó)家發(fā)改委、國(guó)家能源局:推廣不停電作業(yè)技術(shù) 減少停電時(shí)間和停電次數(shù)
2020-09-28獲得電力,供電可靠性,供電企業(yè)
-
碳中和戰(zhàn)略|趙英民副部長(zhǎng)致辭全文
2020-10-19碳中和,碳排放,趙英民 -

深度報(bào)告 | 基于分類監(jiān)管與當(dāng)量協(xié)同的碳市場(chǎng)框架設(shè)計(jì)方案
2020-07-21碳市場(chǎng),碳排放,碳交易 -

碳市場(chǎng)讓重慶能源轉(zhuǎn)型與經(jīng)濟(jì)發(fā)展并進(jìn)
2020-07-21碳市場(chǎng),碳排放,重慶
-
兩部門:推廣不停電作業(yè)技術(shù) 減少停電時(shí)間和停電次數(shù)
2020-09-28獲得電力,供電可靠性,供電企業(yè) -
國(guó)家發(fā)改委、國(guó)家能源局:推廣不停電作業(yè)技術(shù) 減少停電時(shí)間和停電次數(shù)
2020-09-28獲得電力,供電可靠性,供電企業(yè) -
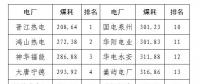
2020年二季度福建省統(tǒng)調(diào)燃煤電廠節(jié)能減排信息披露
2020-07-21火電環(huán)保,燃煤電廠,超低排放
-

四川“專線供電”身陷違法困境
2019-12-16專線供電 -

我國(guó)能源替代規(guī)范法律問題研究(上)
2019-10-31能源替代規(guī)范法律 -

區(qū)域鏈結(jié)構(gòu)對(duì)于數(shù)據(jù)中心有什么影響?這個(gè)影響是好是壞呢!