淺談區(qū)塊鏈技術(shù)與阿里云的探索實踐

作者 | 余珊
本文根據(jù) QCon 北京 2018 站上的演講整理而成,原題《區(qū)塊鏈 Hyperledger Fabric 的落地挑戰(zhàn)與阿里云探索經(jīng)驗分享》。

這是今天的主題大綱,我們開始先會回顧一下區(qū)塊鏈的概念技術(shù)和業(yè)務(wù),我們會探討一下區(qū)塊鏈在企業(yè)場景落地的一些關(guān)鍵考慮的問題,下面也會介紹一下我們阿里云推出區(qū)塊鏈的一些相關(guān)的工具。最后的話,我們會做一些重點分享,我們在區(qū)塊鏈落地,從規(guī)劃、運維、到應(yīng)用這方面去分享我們的一些探索經(jīng)驗。

首先我們先回顧一下區(qū)塊鏈的基本概念,最近一兩年大家無論主動或被動的已經(jīng)受到了很多區(qū)塊鏈技術(shù)和業(yè)務(wù)科普的洗禮。 首先,區(qū)塊鏈是什么?它是一種分布式共享賬本技術(shù),在參與區(qū)塊鏈網(wǎng)絡(luò)的交易各方以及監(jiān)管方可以共享賬本,這個賬本有這樣一個特性,一旦交易經(jīng)過各方的確認,交易的數(shù)據(jù)就不可實現(xiàn)任何的更改。第二,交易歷史是全程可以回溯的,交易信息里面涉及到些商業(yè)機密,交易方的身份等等都得到隱私的保護,交易本身是通過智能合約 Smart Contract 去自動執(zhí)行的。
區(qū)塊鏈的類型有很多,公有鏈、私有鏈、聯(lián)盟鏈等等,在阿里云這邊,我們的工作更多是關(guān)注聯(lián)盟鏈這種類型。區(qū)塊鏈本身不是一個全新的技術(shù),它是基于一些業(yè)界已有的關(guān)鍵技術(shù)去構(gòu)成的一套體系,包括比如基于拜占庭等共識算法。還有基于密碼學(xué)的一些技術(shù)基礎(chǔ),像非對稱密鑰、數(shù)字簽名等等技術(shù)。此外,它本質(zhì)是一個分布式系統(tǒng)架構(gòu),所以會涉及到一些分布式計算如高可用,水平擴展,Gossip 通訊協(xié)議等等一些技術(shù)。
區(qū)塊鏈要解決的核心問題,是在缺乏信任基礎(chǔ)的商業(yè)環(huán)境下,各方如何來進行交易和協(xié)作的問題。大家看到有很多講區(qū)塊鏈價值,比如說提升了協(xié)作效率,降低了時間成本,提升了信息透明度等等,根源都在于我們?nèi)狈π湃我约盎蛐湃味炔蛔愕那闆r下,在傳統(tǒng)模式引入的各種冗余的流程、冗余的模式、中介機構(gòu)所導(dǎo)致的。同時區(qū)塊鏈也會帶來像去中心化 / 多中心化這樣的結(jié)果,但是去中心化不是區(qū)塊鏈的目的,真正目的是要解決跨企業(yè)的信任問題。

其實業(yè)界在區(qū)塊鏈的實現(xiàn)技術(shù)上有很豐富的類型,這列舉了一些影響力比較大的主流技術(shù)。其中一個在開源界影響比較大的是 Linux 基金會 Hyperledger 這樣一個傘形項目,下面包含了很多區(qū)塊鏈技術(shù)實現(xiàn)以及一些工具。其中獲得最廣泛采用的是 Hyperledger Fabric 這個項目,項目初期是由 IBM 和 DAH 一起貢獻的源代碼,現(xiàn)在全球參與的項目成員數(shù)量已經(jīng)是非常多了,其次還有 Sawtooth,Iroha 等等。
其他的實現(xiàn)技術(shù)還有以太坊,以太坊早期是從以太幣發(fā)展起來的,那么現(xiàn)在也有一些面向商業(yè)場景以及聯(lián)盟鏈的分支技術(shù)。還有像 R3 Corda,R3 Corda 是面向金融場景開發(fā)的一種區(qū)塊鏈技術(shù),與之相比, Hyperledger Fabric 更多是面向通用行業(yè)、通用業(yè)務(wù)場景的。此外還有各個廠商自研的區(qū)塊鏈技術(shù),例如阿里這邊有螞蟻金服自研的螞蟻區(qū)塊鏈技術(shù)。

這一頁大概總結(jié)一下在 Hyperledger Fabric 的發(fā)展過程中它的架構(gòu)演進的過程,在 Hyperledger Fabric v0.6 采用的是左圖這樣一種架構(gòu)體系。它跟很多廠商自研的區(qū)塊鏈技術(shù)是一種類似的架構(gòu),它主要由 Peer 節(jié)點構(gòu)成,Peer 上面保存了賬本,賬本在不同 Peer 之間會共享以及同步復(fù)制,Peer 上面也會運行共識算法以及智能合約。后來 Hyperledger Fabric 從 1.0 開始采用了一種新的架構(gòu),它的優(yōu)勢是可以實現(xiàn)架構(gòu)的水平擴展和解耦,它的共識算法可以實現(xiàn)可插拔的模式,來解決傳統(tǒng)比如拜占庭共識算法帶來的節(jié)點數(shù)要在一開始就固定好,后期無法動態(tài)擴展這些問題。

區(qū)塊鏈的業(yè)務(wù)應(yīng)用場景非常的豐富,相信大家在國內(nèi)外也看到了很多落地的案例,這里我也大概列舉了一些。比如說公益慈善、信用證、資產(chǎn)證券化、資產(chǎn)托管等等,我也會介紹一下在一些重點的場景上面,區(qū)塊鏈的價值以及面臨的挑戰(zhàn)是什么。
比如說在商品溯源這個場景,區(qū)塊鏈實現(xiàn)的是商品從出廠到中間經(jīng)過物流、倉儲、經(jīng)銷商、零售、電商平臺,再到消費者,這個過程中它的產(chǎn)品溯源信息的不可篡改的特性。但是在這業(yè)務(wù)場景落地有一個很關(guān)鍵的挑戰(zhàn),雖然區(qū)塊鏈實現(xiàn)了鏈上數(shù)據(jù)的不可篡改,但也要解決實體商品本身如何跟區(qū)塊鏈上的數(shù)據(jù)做一個可信的關(guān)聯(lián)。因為我們要避免出現(xiàn)標簽是真的,區(qū)塊鏈溯源數(shù)據(jù)都是真的,但是實體商品是假的。這個環(huán)節(jié)不是區(qū)塊鏈就可以把它全部解決,我們還要結(jié)合像防偽技術(shù)等等,去形成更完整的溯源方案。
在數(shù)字內(nèi)容版權(quán)這個領(lǐng)域,區(qū)塊鏈的價值在于可實現(xiàn)對無論視頻、音頻、電影、音樂、電子書等等內(nèi)容的創(chuàng)作權(quán)的存證確認,以及更進一步的,在消費、交易環(huán)節(jié)給創(chuàng)作者做公平的收益分享。要在這個場景落地也有一些很關(guān)鍵的挑戰(zhàn),就是怎么保證在內(nèi)容、交易和消費的環(huán)節(jié),將消費數(shù)字內(nèi)容的工具和流程均納入到區(qū)塊鏈這種利益分配的體系,這是區(qū)塊鏈在這個場景落地的一個很關(guān)鍵挑戰(zhàn)。
在供應(yīng)鏈金融,核心企業(yè)在供應(yīng)鏈中往往處于很強勢的地位,那么如何把核心企業(yè)的信用資質(zhì)傳導(dǎo)到供應(yīng)鏈的上游和下游,比如上游的多級供應(yīng)商,以及下游的多級經(jīng)銷商,讓他們可以基于核心企業(yè)的背書,得到更低成本、更高效的融資,這是供應(yīng)鏈金融區(qū)塊鏈一個核心價值。但里面的關(guān)鍵落地挑戰(zhàn)在于,怎么能吸引到整個供應(yīng)鏈上下游那么多企業(yè)都愿意參與到區(qū)塊鏈這個業(yè)務(wù)體系來。
基因醫(yī)療數(shù)據(jù)存儲和共享,這個場景有一定共通性,因為它也會適用于像金融大數(shù)據(jù),或者是互聯(lián)網(wǎng)大數(shù)據(jù),這些數(shù)據(jù)資產(chǎn)的存儲和共享。這里面區(qū)塊鏈價值在于,可以對數(shù)據(jù)資產(chǎn)的所有權(quán)做一個確認,并且在這種數(shù)據(jù)資產(chǎn)交易的平臺或者體系里面,可以根據(jù)所有者的這些不可篡改的確權(quán)存證來保證數(shù)據(jù)交易的利益的在各方實現(xiàn)分配。但里面也有一些關(guān)鍵挑戰(zhàn),例如怎樣去保證數(shù)據(jù)交易在數(shù)據(jù)使用這個環(huán)節(jié),數(shù)據(jù)資產(chǎn)不會發(fā)生泄露或者被違規(guī)使用,或者被購買方二次倒賣等等,這是數(shù)據(jù)資產(chǎn)業(yè)務(wù)落地的一個關(guān)鍵挑戰(zhàn)。各個行業(yè)區(qū)塊鏈落地也都面臨著很多挑戰(zhàn),上面舉的是一些比較典型的例子。
對于企業(yè)來說,現(xiàn)在關(guān)心區(qū)塊鏈,并且想和業(yè)務(wù)結(jié)合的企業(yè)越來越多。我們與阿里云的客戶、以及我們的合作伙伴進行了很多探討,以及內(nèi)部我們也正在開發(fā)一些落地方案。
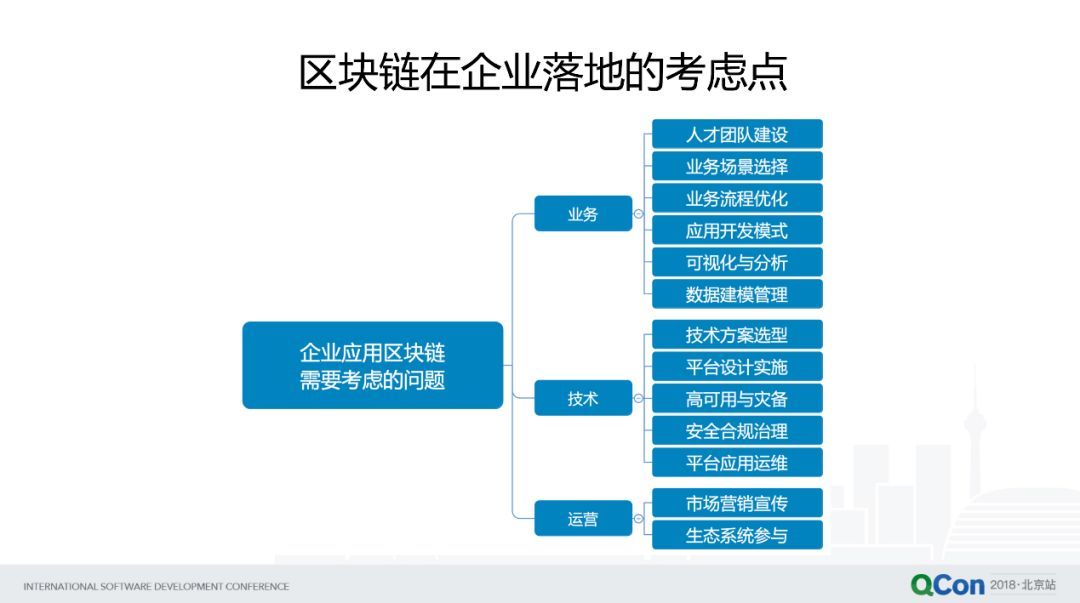
對一個企業(yè)來說,要應(yīng)用區(qū)塊鏈到底需要考慮哪些維度的問題?大概分為這幾個類別。比如說在業(yè)務(wù)方面,我們首先要做一件事是要有“人”的保證,這個人才的團隊包含很多方面,需要區(qū)塊鏈的技術(shù)人才,需要部署區(qū)塊鏈底層,或者業(yè)務(wù)底層的云平臺的技術(shù)人才,需要有業(yè)務(wù)應(yīng)用開發(fā)的團隊去支持,需要有業(yè)務(wù)方面的一些專家,所以這是人才團隊的維度。
另外業(yè)務(wù)場景選擇,有很多企業(yè)場景,如果能用傳統(tǒng)的中心化方案或者系統(tǒng)去解決的話,那么就要反思是否有必要去用區(qū)塊鏈。如果說有一些場景是涉及到跨企業(yè)協(xié)作,并且確實缺乏信任基礎(chǔ)的,這個就可以考慮應(yīng)用區(qū)塊鏈。
下面是業(yè)務(wù)流程優(yōu)化,區(qū)塊鏈在業(yè)務(wù)應(yīng)用里面是有一個特點,尤其在聯(lián)盟鏈,它涉及到跨企業(yè)的業(yè)務(wù)流程,所以不像傳統(tǒng)的流程只限于企業(yè)內(nèi)部,只是幾個部門之間的協(xié)作,跨企業(yè)的業(yè)務(wù)流程需要在保證各方平等、自治的基礎(chǔ)上,建立起業(yè)務(wù)流程以及進一步優(yōu)化,這些都是必須考慮的問題。
應(yīng)用開發(fā)模式,解決的是如何在你的業(yè)務(wù)人員或開發(fā)人員與區(qū)塊鏈底層技術(shù)之間構(gòu)建起一個橋梁,把區(qū)塊鏈底層的這些 API 調(diào)用、SDK 調(diào)用變成你的業(yè)務(wù)模型、業(yè)務(wù)流程,讓業(yè)務(wù)人員能夠理解和使用。接下來是可視化分析,區(qū)塊鏈本身運行是類似于一個黑盒子,如果我們在企業(yè)落地,我們關(guān)心是它對業(yè)務(wù)貢獻的商業(yè)價值,怎樣把這種一個黑盒的系統(tǒng)變成對商業(yè)的決策者來說是可視化、可量化,并且可用于做 BI 分析的設(shè)計。數(shù)據(jù)建模和管理指的是,區(qū)塊鏈里面賬本存儲的是 key value,是區(qū)塊鏈對應(yīng)的業(yè)務(wù)場景的數(shù)據(jù)建模存儲的內(nèi)容。那么區(qū)塊鏈業(yè)務(wù)數(shù)據(jù)怎么和企業(yè)的主數(shù)據(jù)之間去建立起關(guān)聯(lián),以及做后期的數(shù)據(jù)模型的管理?這些也是企業(yè)需要考慮的。
下面的話,像技術(shù)方案選型,就涉及到區(qū)塊鏈技術(shù)本身的不同流派、不同區(qū)塊鏈類型等等的選擇,以及相應(yīng)的開發(fā)編程語言、開發(fā)框架的選擇,還有底層部署云平臺技術(shù)的選擇。平臺設(shè)計實施,這包含了整個平臺方案以及業(yè)務(wù)部署方案的設(shè)計實施。高可用和災(zāi)備,這里面涉及到跨企業(yè)區(qū)塊鏈業(yè)務(wù)協(xié)作體系,怎么既要保證本企業(yè)業(yè)務(wù)服務(wù)的可持續(xù)性,也要保證在跨企業(yè)協(xié)作中,不會因為一個企業(yè)的節(jié)點,導(dǎo)致了整個聯(lián)盟鏈的業(yè)務(wù)的癱瘓,所以這都是要考慮的很關(guān)鍵的問題。
像安全合規(guī)治理,這是大家應(yīng)用區(qū)塊鏈最關(guān)心的一個點,因為我都把我的業(yè)務(wù)數(shù)據(jù)放在一個跨企業(yè)的聯(lián)盟鏈上面,我是非常重視里面的數(shù)據(jù)安全,商業(yè)隱私的保護,尤其大家如果還涉及到,比如說進軍海外市場,涉及到和美國政府或歐盟打交道,這些很嚴格的數(shù)據(jù)保護的要求,隱私保護的政策等等,這方面也是我們應(yīng)用區(qū)塊鏈必須要考慮的。
另外平臺應(yīng)用運維,這里面就涉及到因為區(qū)塊鏈的不可篡改特性,導(dǎo)致上面的配置、數(shù)據(jù)、應(yīng)用的管理相比傳統(tǒng)有很大的不同和挑戰(zhàn)。下面是運營,市場營銷宣傳,我看業(yè)界很多公司做得很好,這塊我就不用多說了。生態(tài)系統(tǒng)參與包含了企業(yè)去應(yīng)用區(qū)塊鏈,同時要考慮,是否要跟外部的,比如說區(qū)塊鏈相關(guān)的官方組織,以及開源社區(qū)的技術(shù)參與,以及業(yè)務(wù)生態(tài)系統(tǒng)的參與,比如說,基于某個業(yè)務(wù)形成的這些行業(yè)聯(lián)盟,以及行業(yè)協(xié)會等等的參與。
所以這里面涉及到的問題是覆蓋了很多維度,今天可能不能對所有問題都有一個標準的答案。但我們會對其中一些地方,分享我們的一些探索經(jīng)驗。

面的話,是介紹我們在探索過程中用到的工具,就是去年 10 月份,我們在杭州云棲大會發(fā)布的基于阿里云容器服務(wù)的區(qū)塊鏈解決方案。這其實是我們在區(qū)塊鏈領(lǐng)域探索的第一小步,目前我們也在緊張地開發(fā)一些更新的產(chǎn)品形態(tài)和更多的落地方案。
這里面它核心解決是什么問題?對很多企業(yè)來說應(yīng)用區(qū)塊鏈,關(guān)注的是怎么快速地去把業(yè)務(wù)和區(qū)塊鏈結(jié)合,實現(xiàn)業(yè)務(wù)應(yīng)用上線,我想聚焦的是業(yè)務(wù)創(chuàng)新本身,沒有足夠的比如人員團隊或者是時間去進行區(qū)塊鏈整個底層的建設(shè),所以這是企業(yè)一方面的訴求。
另一方面的訴求是由區(qū)塊鏈的技術(shù)特性決定的,因為它的不可篡改的特性會導(dǎo)致了在開發(fā)業(yè)務(wù)應(yīng)用的時候,區(qū)塊鏈系統(tǒng)里面的數(shù)據(jù),區(qū)塊鏈的整個網(wǎng)絡(luò)的配置,不是說管理員去改幾個參數(shù),或者是去做 roll back、delete 等等就可以恢復(fù)成一套全新的環(huán)境。你需要把整個環(huán)境鏟掉,然后重新把它再搭建起來才能進下一輪的開發(fā)測試等等。這就導(dǎo)致了在業(yè)務(wù)應(yīng)用的開發(fā)過程迭代的效率問題。這類的話,我們的區(qū)塊鏈解決方案可以提供基于界面化的一鍵自動化配置部署,讓企業(yè)可以在幾分鐘內(nèi)就可以得到一套企業(yè)級的區(qū)塊鏈開發(fā)測試環(huán)境,這是我們當時解決用戶痛點的一個出發(fā)點。

這個是解決方案的大體架構(gòu),這里我也不做太多介紹了。大家可以看一下,這里面體現(xiàn)了如何在 Kubernetes 集群技術(shù)上去搭建一套 Hyperledger Fabric 區(qū)塊鏈服務(wù)的最基本的要素的展現(xiàn),企業(yè)在進行區(qū)塊鏈技術(shù)選型時候也可以參考這些緯度,去選擇區(qū)塊鏈平臺。


下面我們就重點講講我們在這三個領(lǐng)域上面的探索經(jīng)驗。
第一個是基于 Hyperledger Fabric 的業(yè)務(wù)和數(shù)據(jù)存儲容量的估算方法。下面這個圖展示的是 Hyperledger Fabric 的完整交易流程以及部署架構(gòu),給大家介紹一下基于 Hyperledger Fabric 的區(qū)塊鏈交易是怎么進行的。首先業(yè)務(wù)應(yīng)用會通過 CA 服務(wù)去進行身份的注冊以及登錄之后,就可以去連接不同組織的背書 Peer 節(jié)點,把交易請求發(fā)送給背書的 Peer 節(jié)點,進行區(qū)塊鏈交易模擬運行,模擬運行是通過里面的 Chaincode 容器去進行的,再把模擬交易結(jié)果返回給 Client,再發(fā)給上面的 Orderer 服務(wù),去把這些模擬運行的交易結(jié)果變成一個個區(qū)塊,這就是區(qū)塊鏈里面出塊的那個環(huán)節(jié)。Orderer 服務(wù)內(nèi)部是把 transaction 交易信息放到后臺 Kafka 隊列,再從隊列取出后組成一個個區(qū)塊的。組成區(qū)塊之后,Orderer 會把區(qū)塊廣播發(fā)送給整個業(yè)務(wù)網(wǎng)絡(luò)里的 Peer 節(jié)點,每個 Peer 節(jié)點收到這些塊之后,就會對里面的 transaction 做一個 validation,再把里面合法的交易 commit 到區(qū)塊鏈的這些賬本里面,這就是區(qū)塊鏈 Hyperledger Fabric 一個交易的整體流程。
但對一個企業(yè)來說,我如果要搭建一個基于區(qū)塊鏈的業(yè)務(wù)系統(tǒng),我光了解這個流程是不夠的,尤其是企業(yè)的架構(gòu)師、或者預(yù)算和采購的團隊,以及甚至 CTO 他會問這個問題:你這套系統(tǒng)到底能支撐我多大的業(yè)務(wù)量?尤其區(qū)塊鏈里面最重要的是交易數(shù)據(jù),那么為了對交易數(shù)據(jù)做持久化,我要規(guī)劃多大的存儲資源才能滿足我企業(yè)業(yè)務(wù)未來一年、兩年、三年的運行的需要,這是我們遇到的很多客戶在落地前問的第一個問題。

這個問題不好回答,因為由于區(qū)塊鏈比如 Hyperledger Fabric 本身的交易流程以及底層技術(shù)架構(gòu)復(fù)雜性,業(yè)界也沒有很好的估算的方法。我們進行了對 Fabric 架構(gòu)和代碼的分析,以及通過一些容量的測試,得出了一些估算方法,下面跟大家分享一下。
首先我們對整個 Fabric 技術(shù)架構(gòu)的存儲增長的熱點做了一個定性的分析,可以看到在 Orderer 這個節(jié)點,每個 Orderer 它會保存賬本的一個 block file,就是交易歷史文件,它跟我們的交易量是線性相關(guān)的,增長的壓力是比較大的。
其次是 Kafka 集群的隊列,剛才講的在 Orderer 收到交易數(shù)據(jù)以后是放在 Kafka Broker 的隊列里面,這里面也會有數(shù)據(jù)容量的增長,這塊是黃色,代表它增長壓力是中等的,后面會解釋一下。其次在整個網(wǎng)絡(luò)里面每個 Peer 又有兩部分,在 Peer 的 Ledger 里面也有 block file,這塊也是隨著交易量會有一個線性增長。其次 StateDB 是存儲賬本的世界狀態(tài),這一部分也會跟交易相關(guān),但是它不是一個直接線性相關(guān)的關(guān)系。

有了這個定性的分析結(jié)果之后,我們再進一步看看如何定量的去得出估算的結(jié)果。這里是經(jīng)過剛才講的一系列架構(gòu)代碼分析,以及容量測試,得到的一個估算公式。可能它還不是非常完美的,但是在實際應(yīng)用中已經(jīng)能提供非常有用的信息。我大概解釋一下,區(qū)塊鏈有個多鏈的概念,就是 Fabric 有個多鏈的概念,通過 Channel 去實現(xiàn),每個 Channel 代表了一種業(yè)務(wù),這種業(yè)務(wù)有獨立的賬本,跟其他的 Channel 是隔離的關(guān)系。我們可以讓用戶提供一個輸入,比如說它可以估算每種業(yè)務(wù)每天平均交易筆數(shù)作為基礎(chǔ),因為這里我們進行的是容量估計,而不是做 Performance 峰值估計,這是第一個輸入?yún)?shù)。
其次 Fabric 每一筆交易的基本開銷是 Fabric transaction 這種數(shù)據(jù)結(jié)構(gòu),這個數(shù)據(jù)結(jié)構(gòu)我們分析過代碼,大概是 2.9KB 的大小,但是還有其他附加的,比如說 Index 的一些開銷以及 Block 的一些開銷,我們大概取一個估算值,大概 4K 左右的一個結(jié)果。那么再加上每一筆交易平均業(yè)務(wù)數(shù)據(jù)大小,那就是你的真正交易 Payload 數(shù)據(jù),你想把什么數(shù)據(jù)寫在鏈上,這個 Payload 的大小。這里要乘個 2,乘 2 是個很關(guān)鍵的點,在剛才講的背書交易的過程,它這個交易 transaction 數(shù)據(jù)是包含兩部分,一個叫了 chaincode proposal payload,以及 proposal response payload,它是把我的業(yè)務(wù)數(shù)據(jù)這一部分進行了兩次的表述,在我的 transaction 數(shù)據(jù)結(jié)構(gòu)里面,這就是為什么有乘 2 的原因。
其次就是業(yè)務(wù) Channel 數(shù)量,我搭起來一套 Fabric 區(qū)塊鏈網(wǎng)絡(luò),不希望只服務(wù)于一種業(yè)務(wù),希望可以支持多種業(yè)務(wù),那么要乘上相應(yīng)的業(yè)務(wù) Channel 數(shù)量。要支持業(yè)務(wù)年的時間,還有 Peer 節(jié)點數(shù)量,Peer 節(jié)點是因為每個 Peer 上面會存儲區(qū)塊鏈的 block file 來記錄賬本,乘 2,2 到 1 之間是個很有意思的,它涉及到每個 Peer 既有 block file,也有 StateDB,比如企業(yè)級我們現(xiàn)在用 CoachDB,但這個數(shù)據(jù)特征是跟你的業(yè)務(wù)類型緊密相關(guān)的,如果說你每個交易都是創(chuàng)建一個新的 key value,跟你多筆交易 update 同一個 key value,對 StateDB 的開銷是不一樣的。
另一方面,因為像 CoachDB 它應(yīng)用了 Google 的 Snappy 壓縮技術(shù),真正的交易的 Payload 進到 StateDB 里面存成 key value,它不是原生的數(shù)據(jù)大小,而是它會經(jīng)過一段時間壓縮之后,數(shù)據(jù)量會大大的減小,當然壓縮比例會跟業(yè)務(wù)數(shù)據(jù)的本身這些數(shù)據(jù)的一些特征會有關(guān)系,這就是一個比較彈性的,因為涉及到我剛才講的 StateDB 的特性。此外 Orderer 的節(jié)點數(shù)量,這里面就涉及到,因為 Orderer 它保存了一套完整的數(shù)據(jù)賬本,那么它跟 Peer 的賬本是一致的,這塊還有相應(yīng)的開銷。
然后就是 Kafka,Kafka 的隊列是有一個功能是做 retention period 的保證,經(jīng)過 retention period 之后,它可以把隊列里的消息,就假定是客戶不需要的可以把它清除掉,在 Fabric 里面 kafka Retention 天數(shù)大概是 7 天,當然用戶可以自定義了,7 天的量,再乘以 replica,replica 是 kafka 用來做數(shù)據(jù)的高可用的,同一套數(shù)據(jù)在 kafka 會有多套副本。在 Fabric 里面,kafka replica 數(shù)量是 3,這是只需要保存 7×3 的這樣一個量。這就是整個估算的方法,下面我給出對應(yīng)的 Excel 公式,大家也可以針對你的情況自己得出一套自動計算的估算公式。

面再講講,在運用估算方法以及注意的點,也反映了區(qū)塊鏈這個業(yè)務(wù)應(yīng)用系統(tǒng)一些設(shè)計原則。第一個,每條業(yè)務(wù) channel 它是有總的大小限制,這個來自于哪里呢?因為剛才講到每個 channel 它有一套賬本,賬本核心是 Block,記錄所有的交易數(shù)據(jù)、交易歷史記錄,這個 Block 是以一個個 append-only 類型的文件來存儲,這些文件大概是有 10 的 6 次方這樣的數(shù)量上限,每個大小是 64 兆,乘下來,技術(shù)上大小上限是 61TB。剛才看到估算的這些值,但是它的上限,比如說每個 Order 或者每個 Peer,它上面的業(yè)務(wù)數(shù)據(jù)量是不能超過 block file 的上限的。
第二個就是我們要注意到底什么東西是適合放在區(qū)塊鏈的,這不僅僅是容量規(guī)劃的問題,而是整個業(yè)務(wù)場景選擇的問題,因為首先區(qū)塊鏈的特征是適合保存證據(jù),它不是用來作為原始的數(shù)據(jù)存儲,或大數(shù)據(jù)存儲的基礎(chǔ)設(shè)施。另外的話,如果你的業(yè)務(wù)場景,頻繁地去更新同一個 Key,比如銀行里面轉(zhuǎn)賬、支付交易,那么我們就要思考這種是否適合區(qū)塊鏈一個特質(zhì),因為區(qū)塊鏈在業(yè)界也有一個不成文的共識,它本身不涉及用于支撐高頻交易業(yè)務(wù)的。另外還有 Block 開銷,因為剛才講了 transaction 是封裝在 Block 里面的,這個 Block 本身從數(shù)據(jù)結(jié)構(gòu)上大概有 1.9KB 的基本開銷,Block 數(shù)量跟 transaction 數(shù)量比例是不定的,因為有下面幾個原因,看到數(shù)字貨幣像比特幣,它的出塊是根據(jù)礦工挖礦,也就做一系列的窮舉計算以及做哈希計算得到一個滿足難度條件的隨機數(shù)等等,這是數(shù)字貨幣出塊。
但是在 Fabric 里面出塊,它只需要滿足這樣三條標準,比如 Block 里面包含的 transaction 筆數(shù)達到上限,它就可以去出一個塊。或者是 Block 里面包含的 transaction 總的 byte 字節(jié)數(shù)達到了上限,或者是從第一條 transaction 進入 Block 之后,等待時間到達上限都可以產(chǎn)生一個塊。因為這三條標準導(dǎo)致了 transaction 數(shù)量與 Block 數(shù)量是沒有嚴格的對應(yīng)的關(guān)系,順便說一句,這三個標準跟 IBM MQ 做網(wǎng)絡(luò)批量的高效傳輸三條標準是基本一致的,業(yè)界有很多設(shè)計是很巧合的。

其他還有一些比較次要的考慮因素,比如說 Fabric 容器鏡像開銷,F(xiàn)abric 涉及到容器鏡像從三五百兆再到 1.5G,1.3G 都有,假如說所有的鏡像單獨存成文件,大概是 11G 的開銷,當然如果我們把鏡像存儲在 Docker Registry 里面比如說 Harbor,或者是云上的鏡像服務(wù),它占的實際體積會小很多,因為基于 docker image 分層文件系統(tǒng)的技術(shù)。但是如果對企業(yè)來說可能要考慮,我要備份多少套的鏡像版本來支撐業(yè)務(wù)的升級、回滾,或者是開發(fā)的需要,這是存儲開銷。此外還有業(yè)務(wù)應(yīng)用跟其他軟件的容器鏡像、以及數(shù)據(jù)的存儲備份等等這些開銷,但這些都是相對次要的一些因素。

我們分享完第一個探索經(jīng)驗,下面將從運維角度,怎么對 Hyperledger Fabric 日志來實現(xiàn)企業(yè)級的運維分析。可能在座的很多同仁會有過使用 Fabric 日志的一些經(jīng)驗,比如說我們可以通過像 Kubernetes 控制臺,去查看某一個 Peer 節(jié)點、Orderer 節(jié)點的日志信息,或者通過命令行運行 kubectl logs 或 docker logs 命令,也可以看到每個節(jié)點的容器的日志信息。但問題是這些手段滿足不了企業(yè)級運維和業(yè)務(wù)分析的需求,這里所面向的對象很可能是區(qū)塊鏈運維系統(tǒng)的團隊,甚至某些場合下會涉及到業(yè)務(wù)相關(guān)的團隊。

那么到底企業(yè)級的運維與業(yè)務(wù)分析需要怎樣的 Fabric 日志的工具或者能力呢?其實這種區(qū)塊鏈的業(yè)務(wù)系統(tǒng)可以結(jié)合,比如說云平臺的日志服務(wù),或者像開源的 ELK 方案去搭建出日志分析系統(tǒng),去跟區(qū)塊鏈整合起來。下面舉幾個例子說明我們需要哪些能力。第一個就是我們希望對區(qū)塊鏈業(yè)務(wù)系統(tǒng)的日志實現(xiàn)實時索引以及動態(tài)查詢的能力。比如說這個例子里面,我們是用阿里云的區(qū)塊鏈解決方案整合了阿里云日志服務(wù)來進行示例,這里我們需要對某一個業(yè)務(wù) Channel 來進行實時的索引查詢,來看這個日志的一些分布,以及跟這個業(yè)務(wù) Channel 相關(guān)的日志信息,可以通過關(guān)鍵字,以及像一些類 SQL 的查詢語句來快速實現(xiàn)查詢。
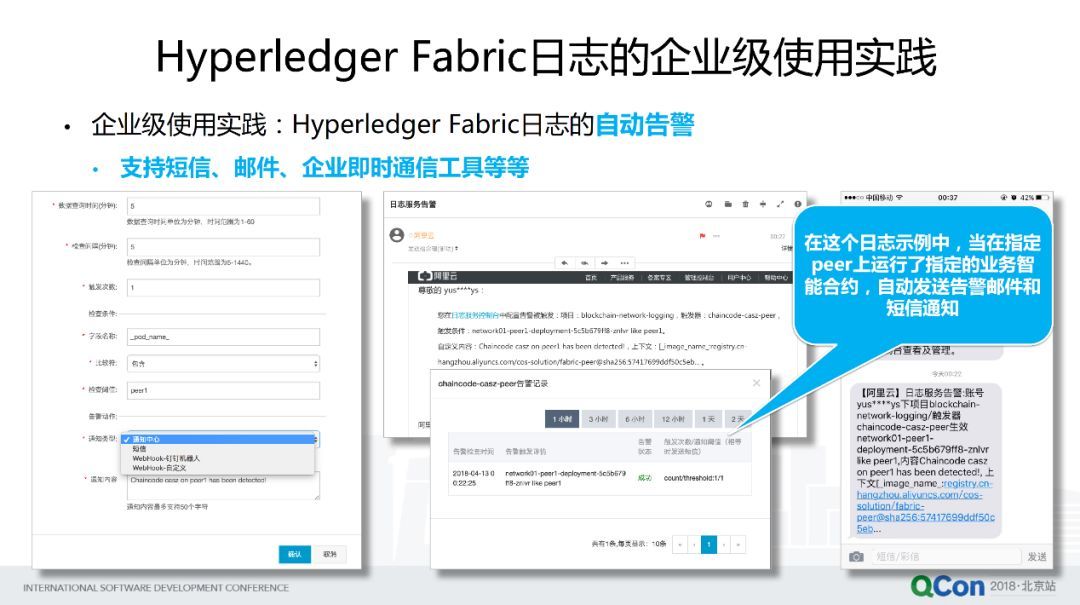
第二個例子,對企業(yè)來說,可能要對一些比較敏感的,或者是高優(yōu)先級,或者是對風(fēng)險有關(guān)的一些日志信息,實現(xiàn)自動告警的功能,并且這些告警可以去對接,比如短信,郵件,企業(yè)及時通信工具如釘釘?shù)鹊纫恍┕ぞ摺T谙旅孢@個示例中,我們就可以去對某一個區(qū)塊鏈應(yīng)用系統(tǒng)來設(shè)定一些告警規(guī)則,檢查在某一個 Peer 節(jié)點上是否有運行某個特定,如某個高敏感性 chaincode 應(yīng)用,設(shè)置這樣一條規(guī)則,在配置好規(guī)則以后,后面當我業(yè)務(wù)系統(tǒng)一旦滿足這個條件,那么就會自動通過郵件,以及短信,向用戶自動發(fā)送告警,并且運維人員在告警記錄里面可以看到告警的這個過程。

再下一個實踐就是,我們企業(yè)是希望能夠獲得一種關(guān)于區(qū)塊鏈業(yè)務(wù)系統(tǒng)運行情況的可視化的統(tǒng)計圖表,以及報表數(shù)據(jù)輸出。這里我們做了一個圖表分析,就是在這幾個 Peer 節(jié)點上,我們其實是做了幾個事情:在一個 Peer 上面調(diào)用了 10 次智能合約,在另一個 Peer 上面調(diào)用了 100 次智能合約。在我們實際的日志的圖表分析里面,就可以看出業(yè)務(wù)調(diào)用情況的體現(xiàn),因為這里基準的這些日志數(shù)量是進行賬本數(shù)據(jù)同步的一些日志,那么額外的這一部分的 Delta 日志數(shù)量是對應(yīng)這 10 次 chaincode 調(diào)用的,另外這部分更大的 Delta 日志數(shù)量就是在這 Peer 上進行 100 次 chaincode 調(diào)用的情況。 這些日志分析圖表可以作為業(yè)務(wù)團隊去分析,比如說在不同業(yè)務(wù)區(qū)域,進入?yún)^(qū)塊鏈業(yè)務(wù)系統(tǒng)流量的差別,或者說跟不同企業(yè)對接的區(qū)塊鏈業(yè)務(wù)系統(tǒng),它的流量差異等等,都可以作為一個業(yè)務(wù)分析的依據(jù),以及說后續(xù)可以導(dǎo)出成 Excel 的形式。
官方微信售電那點事兒")
責(zé)任編輯:售電衡衡
- 相關(guān)閱讀
- 區(qū)塊鏈
- 大數(shù)據(jù)產(chǎn)業(yè)園
- 大數(shù)據(jù)應(yīng)用
-

5大重點任務(wù)11個重點細分 河北加快構(gòu)建省級能源大數(shù)據(jù)中心
-

能源互聯(lián)網(wǎng)注入數(shù)字經(jīng)濟新動能 電力大數(shù)據(jù)實現(xiàn)更多價值
-

中國首個100%利用清潔能源運營的大數(shù)據(jù)產(chǎn)業(yè)園投運
2020-07-21清潔能源,清潔能源消納,青海
-

探索大數(shù)據(jù) 區(qū)塊鏈實現(xiàn)與能源互聯(lián)網(wǎng)良好契合
2020-06-09區(qū)塊鏈,電力行業(yè),能源互聯(lián)網(wǎng) -

基于區(qū)塊鏈的含安全約束分布式電力交易方法
-
區(qū)塊鏈在能源交易與協(xié)同調(diào)度的應(yīng)用前景:提升電力交易的自由度和實時響應(yīng)效率
2019-11-04區(qū)塊鏈在能源交易與協(xié)同